文章目录
- 自己在尝试了官方的代码后就想提高训练的精度就想到了调整学习率,但固定的学习率肯定不适合训练就尝试了几个更改学习率的方法,但没想到居然更差!可能有几个学习率没怎么尝试吧!
-
- 定义一个简单的神经网络模型:y=Wx+b import torch import matplotlib.pyplot as plt %matplotlib inline from torch.optim import * import torch.nn as nn class net(nn.Module): def __init__(self): super(net,self).__init__() self.fc = nn.Linear(1,10) def forward(self,x): return self.fc(x) 直接更改lr的值 model = net() LR = 0.01 optimizer = Adam(model.parameters(),lr = LR) lr_list = [] for epoch in range(100): if epoch % 5 == 0: for p in optimizer.param_groups: p['lr'] *= 0.9 lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') 关键是如下两行能达到手动阶梯式更改,自己也可按需求来更改变换函数 for p in optimizer.param_groups: p['lr'] *= 0.9
- torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1) 参数 含义 lr_lambda 会接收到一个int参数:epoch,然后根据epoch计算出对应的lr。如果设置多个lambda函数的话,会分别作用于Optimizer中的不同的params_group import numpy as np lr_list = [] model = net() LR = 0.01 optimizer = Adam(model.parameters(),lr = LR) lambda1 = lambda epoch:np.sin(epoch) / epoch scheduler = lr_scheduler.LambdaLR(optimizer,lr_lambda = lambda1) for epoch in range(100): scheduler.step() lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1) 每个一定的epoch,lr会自动乘以gamma lr_list = [] model = net() LR = 0.01 optimizer = Adam(model.parameters(),lr = LR) scheduler = lr_scheduler.StepLR(optimizer,step_size=5,gamma = 0.8) for epoch in range(100): scheduler.step() lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1) 三段式lr,epoch进入milestones范围内即乘以gamma,离开milestones范围之后再乘以gamma 这种衰减方式也是在学术论文中最常见的方式,一般手动调整也会采用这种方法。 lr_list = [] model = net() LR = 0.01 optimizer = Adam(model.parameters(),lr = LR) scheduler = lr_scheduler.MultiStepLR(optimizer,milestones=[20,80],gamma = 0.9) for epoch in range(100): scheduler.step() lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1) 每个epoch中lr都乘以gamma lr_list = [] model = net() LR = 0.01 optimizer = Adam(model.parameters(),lr = LR) scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9) for epoch in range(100): scheduler.step() lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1) 参数 含义 T_max 对应1/2个cos周期所对应的epoch数值 eta_min 最小的lr值,默认为0 lr_list = [] model = net() LR = 0.01 optimizer = Adam(model.parameters(),lr = LR) scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max = 20) for epoch in range(100): scheduler.step() lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08) 在发现loss不再降低或者acc不再提高之后,降低学习率。各参数意义如下: 参数 含义 mode 'min'模式检测metric是否不再减小,'max'模式检测metric是否不再增大; factor 触发条件后lr*=factor; patience 不再减小(或增大)的累计次数; verbose 触发条件后print; threshold 只关注超过阈值的显著变化; threshold_mode 有rel和abs两种阈值计算模式,rel规则:max模式下如果超过best(1+threshold)为显著,min模式下如果低于best(1-threshold)为显著;abs规则:max模式下如果超过best+threshold为显著,min模式下如果低于best-threshold为显著; cooldown 触发一次条件后,等待一定epoch再进行检测,避免lr下降过速; min_lr 最小的允许lr; eps 如果新旧lr之间的差异小与1e-8,则忽略此次更新。
-
- 代码中可选的选项有:余弦方式(默认方式,其他两种注释了)、e^-x的方式以及按loss是否不在降低来判断的三种方式,其他就自己测试吧! 训练截图(第一个图为trainingg_loss,第二个为学习率变化曲线)
- import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from datetime import datetime from torch.utils.tensorboard import SummaryWriter from torch.optim import * transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=0) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=0) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') ############################################################################################################################################ device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # Assuming that we are on a CUDA machine, this should print a CUDA device: print(device) print("获取一些随机训练数据") # get some random training images dataiter = iter(trainloader) images, labels = dataiter.next() # functions to show an image def imshow(img): img = img / 2 + 0.5 # unnormalize npimg = img.cpu().numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() # helper function to show an image # (used in the `plot_classes_preds` function below) def matplotlib_imshow(img, one_channel=False): if one_channel: img = img.mean(dim=0) img = img / 2 + 0.5 # unnormalize npimg = img.cpu().numpy() if one_channel: plt.imshow(npimg, cmap="Greys") else: plt.imshow(np.transpose(npimg, (1, 2, 0))) ############################################################################################################################# # 设置tensorBoard # default `log_dir` is "runs" - we'll be more specific here writer = SummaryWriter('runs/image_classify_tensorboard') # get some random training images dataiter = iter(trainloader) images, labels = dataiter.next() # create grid of images img_grid = torchvision.utils.make_grid(images) # show images # matplotlib_imshow(img_grid, one_channel=True) # imshow(img_grid) # write to tensorboard writer.add_image('imag_classify', img_grid) # Tracking model training with TensorBoard # helper functions def images_to_probs(net, images): ''' Generates predictions and corresponding probabilities from a trained network and a list of images ''' output = net(images) # convert output probabilities to predicted class _, preds_tensor = torch.max(output, 1) # preds = np.squeeze(preds_tensor.numpy()) preds = np.squeeze(preds_tensor.cpu().numpy()) return preds, [F.softmax(el, dim=0)[i].item() for i, el in zip(preds, output)] def plot_classes_preds(net, images, labels): ''' Generates matplotlib Figure using a trained network, along with images and labels from a batch, that shows the network's top prediction along with its probability, alongside the actual label, coloring this information based on whether the prediction was correct or not. Uses the "images_to_probs" function. ''' preds, probs = images_to_probs(net, images) # plot the images in the batch, along with predicted and true labels fig = plt.figure(figsize=(12, 48)) for idx in np.arange(4): ax = fig.add_subplot(1, 4, idx+1, xticks=[], yticks=[]) matplotlib_imshow(images[idx], one_channel=True) # imshow(images[idx]) ax.set_title("{0}, {1:.1f}%\n(label: {2})".format( classes[preds[idx]], probs[idx] * 100.0, classes[labels[idx]]), color=("green" if preds[idx]==labels[idx].item() else "red")) return fig ##################################################################################################################################################### # show images imshow(torchvision.utils.make_grid(images)) # print labels print(' '.join('%5s' % classes[labels[j]] for j in range(4))) print("**********************") class Net(nn.Module): def __init__(self): super(Net, self).__init__() # self.conv1 = nn.Conv2d(3, 1000, 3) #输入信号通道3(RGB三通道,即一个彩色图片对于的RGB三个图),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义) # self.pool = nn.MaxPool2d(2, 2)#处理后的特征图片是30×30的,我们对其进行下采样,采样窗口为15X15,最终将其下采样成为一个2×2大小的特征图。 # self.conv2 = nn.Conv2d(1000, 5, 4)#输入信号通道100(RGB三通道),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义) self.conv1 = nn.Conv2d(3, 1000, 5) #输入信号通道3(RGB三通道,即一个彩色图片对于的RGB三个图),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义) self.pool = nn.MaxPool2d(2, 2)#处理后的特征图片是30×30的,我们对其进行下采样,采样窗口为15X15,最终将其下采样成为一个2×2大小的特征图。 self.conv2 = nn.Conv2d(1000, 100, 5)#输入信号通道100(RGB三通道),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义) #三个全连接池 self.fc1 = nn.Linear(100 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 100*5*5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x ############################################################################################################################################ PATH = './cifar_net_64_1000.pth' # 保存模型地址 net = Net() net.to(device) try: net.load_state_dict(torch.load(PATH)) except: print("no model file,it will creat a new file!") # 训练 print("训练") criterion = nn.CrossEntropyLoss() # optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # lr为学习率 # optimizer = optim.SGD(net.parameters(), lr=1e-2, momentum=0.9) # lr为学习率 # LR = 0.01 # optimizer = Adam(net.parameters(),lr = LR) # scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9) #在发现loss不再降低或者acc不再提高之后,降低学习率。 # optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min',factor=0.9,verbose=1,patience=5) #余弦式调整 LR = 0.01 optimizer = Adam(net.parameters(),lr = LR) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max = 20) startTime = datetime.now() for epoch in range(6): # loop over the dataset multiple times if(epoch % 5 == 0): torch.save(net.state_dict(), PATH) print("moodel saved") running_loss = 0.0 for i, data in enumerate(trainloader, 0): # get the inputs; data is a list of [inputs, labels] # inputs, labels = data inputs, labels = data[0].to(device), data[1].to(device) # zero the parameter gradients # optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 反向传播求梯度 # print statistics running_loss += loss.item() if i % 2000 == 1999: # print every 2000 mini-batches print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000)) # scheduler.step(running_loss/2000) scheduler.step()#学习率的更新 print('[%d, %5d] lr:%.5f' %(epoch + 1, i + 1, optimizer.state_dict()['param_groups'][0]['lr'])) # 把数据写入tensorflow # ...log the running loss writer.add_scalar('image training loss', running_loss / 2000, epoch * len(trainloader) + i) writer.add_scalar('lr', optimizer.state_dict()['param_groups'][0]['lr'], epoch * len(trainloader) + i) # ...log a Matplotlib Figure showing the model's predictions on a # random mini-batch # writer.add_figure('predictions vs. actuals', # plot_classes_preds(net, inputs, labels), # global_step=epoch * len(trainloader) + i) running_loss = 0.0 torch.save(net.state_dict(), PATH) print('Finished Training') print("Time taken:", datetime.now() - startTime) print("***************************") ############################################################################################################################################ #获取一些随机测试数据 print("获取一些随机测试数据") dataiter = iter(testloader) images, labels = dataiter.next() # print images imshow(torchvision.utils.make_grid(images)) print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4))) # 恢复模型并测试 net = Net() net.load_state_dict(torch.load(PATH)) outputs = net(images) _, predicted = torch.max(outputs, 1) print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) print("**********************") print("输出训练得到的准确度") # 输出训练得到的准确度 correct = 0 total = 0 with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %d %%' % ( 100 * correct / total)) class_correct = list(0. for i in range(10)) class_total = list(0. for i in range(10)) with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs, 1) c = (predicted == labels).squeeze() for i in range(4): label = labels[i] class_correct[label] += c[i].item() class_total[label] += 1 for i in range(10): print('Accuracy of %5s : %2d %%' % ( classes[i], 100 * class_correct[i] / class_total[i]))
- 在PyTorch中,学习率的更新是通过 scheduler.step() ,而我们知道影响学习率的一个重要参数就是epoch,这里需要注意的是在执行一次 scheduler.step() 之后, epoch 会加1,因此 scheduler.step() 要放在 epoch 的 for 循环当中执行。
- PyTorch安装 用PyTorch训练一个图像分类 PyTorch的TensorBoard用法示例 理解CNN参数及PyTorch实例
- pytorch 动态调整学习率 https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate PyTorch学习之六个学习率调整策略 Pytorch学习笔记(六):学习率 Pytorch(0)降低学习率torch.optim.lr_scheduler.ReduceLROnPlateau类 PyTorch 学习笔记(八):PyTorch的六个学习率调整方法 Pytorch中的学习率衰减方法
自己在尝试了官方的代码后就想提高训练的精度就想到了调整学习率,但固定的学习率肯定不适合训练就尝试了几个更改学习率的方法,但没想到居然更差!可能有几个学习率没怎么尝试吧!
自己在尝试了官方的代码后就想提高训练的精度就想到了调整学习率,但固定的学习率肯定不适合训练就尝试了几个更改学习率的方法,但没想到居然更差!可能有几个学习率没怎么尝试吧!
- 定义一个简单的神经网络模型:y=Wx+b
import torch
import matplotlib.pyplot as plt
%matplotlib inline
from torch.optim import *
import torch.nn as nn
class net(nn.Module):
def __init__(self):
super(net,self).__init__()
self.fc = nn.Linear(1,10)
def forward(self,x):
return self.fc(x)
- 直接更改lr的值
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
lr_list = []
for epoch in range(100):
if epoch % 5 == 0:
for p in optimizer.param_groups:
p['lr'] *= 0.9
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
import torch
import matplotlib.pyplot as plt
%matplotlib inline
from torch.optim import *
import torch.nn as nn
class net(nn.Module):
def __init__(self):
super(net,self).__init__()
self.fc = nn.Linear(1,10)
def forward(self,x):
return self.fc(x)
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
lr_list = []
for epoch in range(100):
if epoch % 5 == 0:
for p in optimizer.param_groups:
p['lr'] *= 0.9
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
关键是如下两行能达到手动阶梯式更改,自己也可按需求来更改变换函数
for p in optimizer.param_groups:
p['lr'] *= 0.9

- torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
| 参数 | 含义 |
|---|---|
| lr_lambda | 会接收到一个int参数:epoch,然后根据epoch计算出对应的lr。如果设置多个lambda函数的话,会分别作用于Optimizer中的不同的params_group |
import numpy as np
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
lambda1 = lambda epoch:np.sin(epoch) / epoch
scheduler = lr_scheduler.LambdaLR(optimizer,lr_lambda = lambda1)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
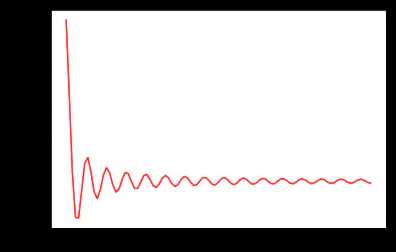
- torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
每个一定的epoch,lr会自动乘以gamma
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.StepLR(optimizer,step_size=5,gamma = 0.8)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
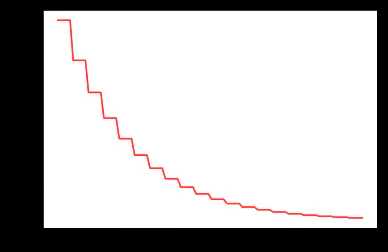
- torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
三段式lr,epoch进入milestones范围内即乘以gamma,离开milestones范围之后再乘以gamma
这种衰减方式也是在学术论文中最常见的方式,一般手动调整也会采用这种方法。
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.MultiStepLR(optimizer,milestones=[20,80],gamma = 0.9)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
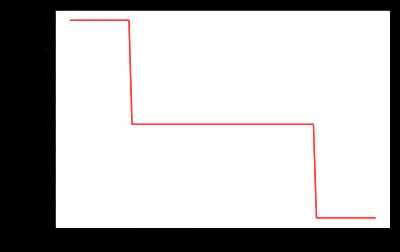
- torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
每个epoch中lr都乘以gamma
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
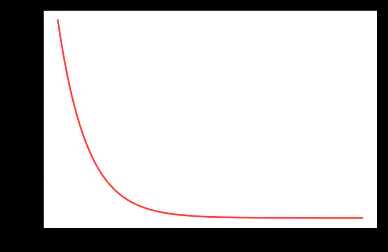
- torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
| 参数 | 含义 |
|---|---|
| T_max | 对应1/2个cos周期所对应的epoch数值 |
| eta_min | 最小的lr值,默认为0 |
lr_list = []
model = net()
LR = 0.01
optimizer = Adam(model.parameters(),lr = LR)
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max = 20)
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
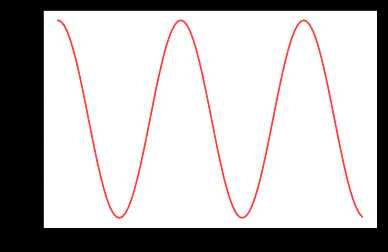
- torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
在发现loss不再降低或者acc不再提高之后,降低学习率。各参数意义如下:
| 参数 | 含义 |
|---|---|
| mode | 'min'模式检测metric是否不再减小,'max'模式检测metric是否不再增大; |
| factor | 触发条件后lr*=factor; |
| patience | 不再减小(或增大)的累计次数; |
| verbose | 触发条件后print; |
| threshold | 只关注超过阈值的显著变化; |
| threshold_mode | 有rel和abs两种阈值计算模式,rel规则:max模式下如果超过best(1+threshold)为显著,min模式下如果低于best(1-threshold)为显著;abs规则:max模式下如果超过best+threshold为显著,min模式下如果低于best-threshold为显著; |
| cooldown | 触发一次条件后,等待一定epoch再进行检测,避免lr下降过速; |
| min_lr | 最小的允许lr; |
| eps | 如果新旧lr之间的差异小与1e-8,则忽略此次更新。 |
- 代码中可选的选项有:余弦方式(默认方式,其他两种注释了)、e^-x的方式以及按loss是否不在降低来判断的三种方式,其他就自己测试吧!
-
训练截图(第一个图为trainingg_loss,第二个为学习率变化曲线)
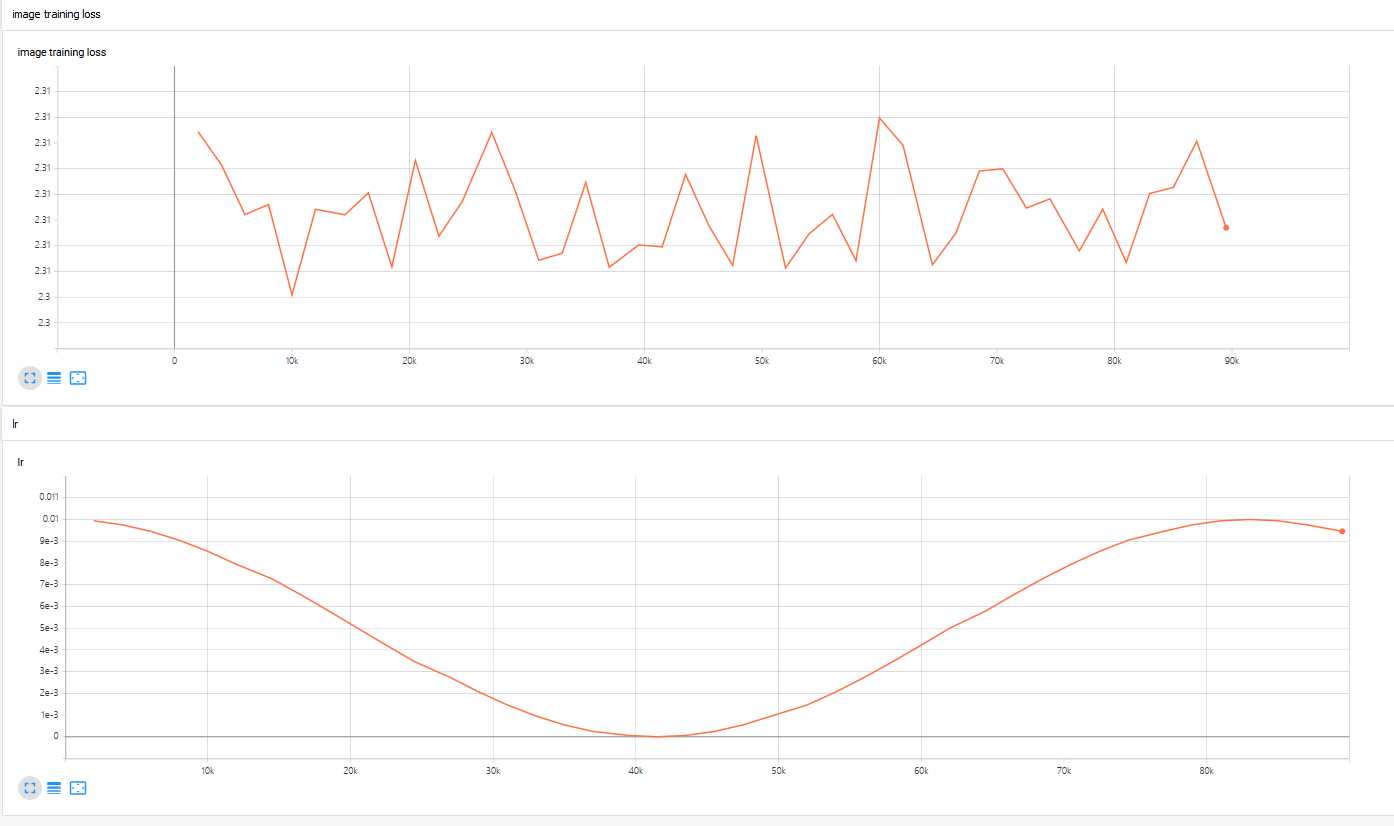
训练截图(第一个图为trainingg_loss,第二个为学习率变化曲线)
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from datetime import datetime
from torch.utils.tensorboard import SummaryWriter
from torch.optim import *
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
############################################################################################################################################
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)
print("获取一些随机训练数据")
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.cpu().numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# helper function to show an image
# (used in the `plot_classes_preds` function below)
def matplotlib_imshow(img, one_channel=False):
if one_channel:
img = img.mean(dim=0)
img = img / 2 + 0.5 # unnormalize
npimg = img.cpu().numpy()
if one_channel:
plt.imshow(npimg, cmap="Greys")
else:
plt.imshow(np.transpose(npimg, (1, 2, 0)))
#############################################################################################################################
# 设置tensorBoard
# default `log_dir` is "runs" - we'll be more specific here
writer = SummaryWriter('runs/image_classify_tensorboard')
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# create grid of images
img_grid = torchvision.utils.make_grid(images)
# show images
# matplotlib_imshow(img_grid, one_channel=True)
# imshow(img_grid)
# write to tensorboard
writer.add_image('imag_classify', img_grid)
# Tracking model training with TensorBoard
# helper functions
def images_to_probs(net, images):
'''
Generates predictions and corresponding probabilities from a trained
network and a list of images
'''
output = net(images)
# convert output probabilities to predicted class
_, preds_tensor = torch.max(output, 1)
# preds = np.squeeze(preds_tensor.numpy())
preds = np.squeeze(preds_tensor.cpu().numpy())
return preds, [F.softmax(el, dim=0)[i].item() for i, el in zip(preds, output)]
def plot_classes_preds(net, images, labels):
'''
Generates matplotlib Figure using a trained network, along with images
and labels from a batch, that shows the network's top prediction along
with its probability, alongside the actual label, coloring this
information based on whether the prediction was correct or not.
Uses the "images_to_probs" function.
'''
preds, probs = images_to_probs(net, images)
# plot the images in the batch, along with predicted and true labels
fig = plt.figure(figsize=(12, 48))
for idx in np.arange(4):
ax = fig.add_subplot(1, 4, idx+1, xticks=[], yticks=[])
matplotlib_imshow(images[idx], one_channel=True)
# imshow(images[idx])
ax.set_title("{0}, {1:.1f}%\n(label: {2})".format(
classes[preds[idx]],
probs[idx] * 100.0,
classes[labels[idx]]),
color=("green" if preds[idx]==labels[idx].item() else "red"))
return fig
#####################################################################################################################################################
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
print("**********************")
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# self.conv1 = nn.Conv2d(3, 1000, 3) #输入信号通道3(RGB三通道,即一个彩色图片对于的RGB三个图),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义)
# self.pool = nn.MaxPool2d(2, 2)#处理后的特征图片是30×30的,我们对其进行下采样,采样窗口为15X15,最终将其下采样成为一个2×2大小的特征图。
# self.conv2 = nn.Conv2d(1000, 5, 4)#输入信号通道100(RGB三通道),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义)
self.conv1 = nn.Conv2d(3, 1000, 5) #输入信号通道3(RGB三通道,即一个彩色图片对于的RGB三个图),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义)
self.pool = nn.MaxPool2d(2, 2)#处理后的特征图片是30×30的,我们对其进行下采样,采样窗口为15X15,最终将其下采样成为一个2×2大小的特征图。
self.conv2 = nn.Conv2d(1000, 100, 5)#输入信号通道100(RGB三通道),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义)
#三个全连接池
self.fc1 = nn.Linear(100 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 100*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
############################################################################################################################################
PATH = './cifar_net_64_1000.pth' # 保存模型地址
net = Net()
net.to(device)
try:
net.load_state_dict(torch.load(PATH))
except:
print("no model file,it will creat a new file!")
# 训练
print("训练")
criterion = nn.CrossEntropyLoss()
# optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # lr为学习率
# optimizer = optim.SGD(net.parameters(), lr=1e-2, momentum=0.9) # lr为学习率
# LR = 0.01
# optimizer = Adam(net.parameters(),lr = LR)
# scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
#在发现loss不再降低或者acc不再提高之后,降低学习率。
# optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
# scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min',factor=0.9,verbose=1,patience=5)
#余弦式调整
LR = 0.01
optimizer = Adam(net.parameters(),lr = LR)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max = 20)
startTime = datetime.now()
for epoch in range(6): # loop over the dataset multiple times
if(epoch % 5 == 0):
torch.save(net.state_dict(), PATH)
print("moodel saved")
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
# inputs, labels = data
inputs, labels = data[0].to(device), data[1].to(device)
# zero the parameter gradients
# optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step() # 反向传播求梯度
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
# scheduler.step(running_loss/2000)
scheduler.step()#学习率的更新
print('[%d, %5d] lr:%.5f' %(epoch + 1, i + 1, optimizer.state_dict()['param_groups'][0]['lr']))
# 把数据写入tensorflow
# ...log the running loss
writer.add_scalar('image training loss',
running_loss / 2000,
epoch * len(trainloader) + i)
writer.add_scalar('lr',
optimizer.state_dict()['param_groups'][0]['lr'],
epoch * len(trainloader) + i)
# ...log a Matplotlib Figure showing the model's predictions on a
# random mini-batch
# writer.add_figure('predictions vs. actuals',
# plot_classes_preds(net, inputs, labels),
# global_step=epoch * len(trainloader) + i)
running_loss = 0.0
torch.save(net.state_dict(), PATH)
print('Finished Training')
print("Time taken:", datetime.now() - startTime)
print("***************************")
############################################################################################################################################
#获取一些随机测试数据
print("获取一些随机测试数据")
dataiter = iter(testloader)
images, labels = dataiter.next()
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
# 恢复模型并测试
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
print("**********************")
print("输出训练得到的准确度")
# 输出训练得到的准确度
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from datetime import datetime
from torch.utils.tensorboard import SummaryWriter
from torch.optim import *
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
############################################################################################################################################
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)
print("获取一些随机训练数据")
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.cpu().numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# helper function to show an image
# (used in the `plot_classes_preds` function below)
def matplotlib_imshow(img, one_channel=False):
if one_channel:
img = img.mean(dim=0)
img = img / 2 + 0.5 # unnormalize
npimg = img.cpu().numpy()
if one_channel:
plt.imshow(npimg, cmap="Greys")
else:
plt.imshow(np.transpose(npimg, (1, 2, 0)))
#############################################################################################################################
# 设置tensorBoard
# default `log_dir` is "runs" - we'll be more specific here
writer = SummaryWriter('runs/image_classify_tensorboard')
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# create grid of images
img_grid = torchvision.utils.make_grid(images)
# show images
# matplotlib_imshow(img_grid, one_channel=True)
# imshow(img_grid)
# write to tensorboard
writer.add_image('imag_classify', img_grid)
# Tracking model training with TensorBoard
# helper functions
def images_to_probs(net, images):
'''
Generates predictions and corresponding probabilities from a trained
network and a list of images
'''
output = net(images)
# convert output probabilities to predicted class
_, preds_tensor = torch.max(output, 1)
# preds = np.squeeze(preds_tensor.numpy())
preds = np.squeeze(preds_tensor.cpu().numpy())
return preds, [F.softmax(el, dim=0)[i].item() for i, el in zip(preds, output)]
def plot_classes_preds(net, images, labels):
'''
Generates matplotlib Figure using a trained network, along with images
and labels from a batch, that shows the network's top prediction along
with its probability, alongside the actual label, coloring this
information based on whether the prediction was correct or not.
Uses the "images_to_probs" function.
'''
preds, probs = images_to_probs(net, images)
# plot the images in the batch, along with predicted and true labels
fig = plt.figure(figsize=(12, 48))
for idx in np.arange(4):
ax = fig.add_subplot(1, 4, idx+1, xticks=[], yticks=[])
matplotlib_imshow(images[idx], one_channel=True)
# imshow(images[idx])
ax.set_title("{0}, {1:.1f}%\n(label: {2})".format(
classes[preds[idx]],
probs[idx] * 100.0,
classes[labels[idx]]),
color=("green" if preds[idx]==labels[idx].item() else "red"))
return fig
#####################################################################################################################################################
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
print("**********************")
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# self.conv1 = nn.Conv2d(3, 1000, 3) #输入信号通道3(RGB三通道,即一个彩色图片对于的RGB三个图),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义)
# self.pool = nn.MaxPool2d(2, 2)#处理后的特征图片是30×30的,我们对其进行下采样,采样窗口为15X15,最终将其下采样成为一个2×2大小的特征图。
# self.conv2 = nn.Conv2d(1000, 5, 4)#输入信号通道100(RGB三通道),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义)
self.conv1 = nn.Conv2d(3, 1000, 5) #输入信号通道3(RGB三通道,即一个彩色图片对于的RGB三个图),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义)
self.pool = nn.MaxPool2d(2, 2)#处理后的特征图片是30×30的,我们对其进行下采样,采样窗口为15X15,最终将其下采样成为一个2×2大小的特征图。
self.conv2 = nn.Conv2d(1000, 100, 5)#输入信号通道100(RGB三通道),卷积核(Kernel,卷积核,有时也称为filter)尺寸:3,卷积产生100个特征图(该数字为自己填写的,可大可小,但超出图片像素综合则感觉毫无意义)
#三个全连接池
self.fc1 = nn.Linear(100 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 100*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
############################################################################################################################################
PATH = './cifar_net_64_1000.pth' # 保存模型地址
net = Net()
net.to(device)
try:
net.load_state_dict(torch.load(PATH))
except:
print("no model file,it will creat a new file!")
# 训练
print("训练")
criterion = nn.CrossEntropyLoss()
# optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # lr为学习率
# optimizer = optim.SGD(net.parameters(), lr=1e-2, momentum=0.9) # lr为学习率
# LR = 0.01
# optimizer = Adam(net.parameters(),lr = LR)
# scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
#在发现loss不再降低或者acc不再提高之后,降低学习率。
# optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
# scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min',factor=0.9,verbose=1,patience=5)
#余弦式调整
LR = 0.01
optimizer = Adam(net.parameters(),lr = LR)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max = 20)
startTime = datetime.now()
for epoch in range(6): # loop over the dataset multiple times
if(epoch % 5 == 0):
torch.save(net.state_dict(), PATH)
print("moodel saved")
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
# inputs, labels = data
inputs, labels = data[0].to(device), data[1].to(device)
# zero the parameter gradients
# optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step() # 反向传播求梯度
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
# scheduler.step(running_loss/2000)
scheduler.step()#学习率的更新
print('[%d, %5d] lr:%.5f' %(epoch + 1, i + 1, optimizer.state_dict()['param_groups'][0]['lr']))
# 把数据写入tensorflow
# ...log the running loss
writer.add_scalar('image training loss',
running_loss / 2000,
epoch * len(trainloader) + i)
writer.add_scalar('lr',
optimizer.state_dict()['param_groups'][0]['lr'],
epoch * len(trainloader) + i)
# ...log a Matplotlib Figure showing the model's predictions on a
# random mini-batch
# writer.add_figure('predictions vs. actuals',
# plot_classes_preds(net, inputs, labels),
# global_step=epoch * len(trainloader) + i)
running_loss = 0.0
torch.save(net.state_dict(), PATH)
print('Finished Training')
print("Time taken:", datetime.now() - startTime)
print("***************************")
############################################################################################################################################
#获取一些随机测试数据
print("获取一些随机测试数据")
dataiter = iter(testloader)
images, labels = dataiter.next()
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
# 恢复模型并测试
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
print("**********************")
print("输出训练得到的准确度")
# 输出训练得到的准确度
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
在PyTorch中,学习率的更新是通过 scheduler.step() ,而我们知道影响学习率的一个重要参数就是epoch,这里需要注意的是在执行一次 scheduler.step() 之后, epoch 会加1,因此 scheduler.step() 要放在 epoch 的 for 循环当中执行。




