文章目录
- 搜索引擎 全文搜索引擎 自然语言处理,百度等等 垂直搜索引擎 有明确搜索目的 搜索引擎应该具备的要求 查询快 高效的压缩算法 快速的编解码速度 结果准确 结果丰富 面对海量数据,如何实现高效查询? 索引 MySQL索引结构 B Trees B+Trees MySQL索引能解决大数据检索得问题吗? 索引往往字段很长,如果使用B+Trees,树可能很深,IO很可怕。 索引可能会失效 精准度差
- _doc 8.x版本已废弃
- 基于REST风格的API 创建索引 PUT /index?pretty 查询索引 GET _cat/indices?v 删除索引 DELETE /index?pretty 插入数据 PUT /index/_doc/id { JSON 数据 } 替换 全量替换 指定字段更新 PUT /product/_doc/1 { "price":3999 } POST /product/_update/1 { "doc": { "price":5999 } } 删除数据 DELETE /index/type/id
- 概念
定义文档及其包含的字段的存储和索引方式的过程,类似于"表结构"
映射方式
dynamic mapping(动态/自动映射)
expllcit mapping(静态/手工/显示映射)
数据类型
参数
- GET /index/_mapping
-
- 数字类型 long integer short byte double float half_float scaled_float unsigned_long Keywords:(关键词字段常用于排序、汇总和term查询) keyword:适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能通过精确值(exact value)搜索到。id应该用可以word constant_keyword : 始终包含相同值的关键词字段 wildcard: 可针对于类似grep的通配符查询优化日志行和类似的关键字值。 Dates(时间类型) date date_nannos alias 为现有字段设置别名 binary 二进制 range:区间类型 integer_range float_range long_range double_range date_range text: 该字段适用于全文搜索的 字段内容会被分析 不用于排序,很少用于聚合
- object 适用于单个JSON对象 nested 适用于JSON对象数组 flattened 允许将整个JSON对象索引为单个字段
- geo-point: 经纬度积分 geo-shape:用于多边形等复杂形状 point:笛卡尔坐标点 shape: 笛卡尔任意几何图形
- IP地址:IPV4/6 compietion : 提供自动完成建议 token_count : 计算字符串中令牌的数量 murmur3 : 在索引时计算值的哈希并将其存储在索引中 annotated-text : 索引包含特殊标记的文本(通常用于标识命名实体) precolator:接受来自query-dsl的查询 join:为同一索引内的文档定义父/子关系 rank_features: 记录数字功能以提高查询时的点击率 dense_vector: 记录浮点值的密集向量 sparse_vector: 记录浮点值的稀疏向量 search-as-you-type: 争对查询优化的文本字段,以实现按需输入的完成 histogram: 用于百分位数聚合的预聚合数值 constant_keyword: keyword 当前文档都具有相同值时的情况的专业化
- 在ElasticSearch中,数组不需要专用的字段数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的值必需具有相同的数据类型。
- date_nanos: date_plus 纳秒 features:
-
- JSON type 域 type 布尔型: true 或者 false boolean 整数: 123 long 浮点数: 123.45 double 字符串,有效日期: 2014-09-15 date 字符串: foo bar 如果不是数字和字符串类型,会被映射为text和keyword类型 对象 object 数组 取决于数组中的第一个有效值的数据类型 其它类型必须手动映射
- # 添加 PUT /index_name { "mappings": { "properties": { "date":{ "type":"date" }, "name":{ "type":"text", "analyzer": "english" }, "user_id":{ "type":"long" } } } } # 修改 POST /index_name { "mappints":{ "properties": { "name":{ "type":"keyword" } } } }
- 参数 说明 index 是否创建该字段的倒排索引,默认为true。如果不创建索引,该字段不会通过索引被搜索到,但仍然会在source元数据中展示 analyzer 指定分析器(character filter、tokenizer、token filters) boost 针对当前字段相关度的评分权值,默认为1 coerce 是否允许强制类似转化 true "1" => 1 false "1"<= 1 copy_to 该字段运行将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询 doc_values 为了提升排序和聚合效率,默认为true。如果确定不需要对该字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间(不支持text和annotated_text) dynamic ? 控制是否可以动态添加新字段,默认为true(即新检测的字段将添加到映射中)。false时表示新检测的字段将被忽略,这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中,这些字段不会添加到映射中,必须显式添加新字段。strict:如果检测到新字段,则会引发异常并拒绝文档,必须将新字段显式添加到映射中。 eager_global_odrinals 用于聚合的字段上,优化聚合性能。Frozen_indices(冻结索引):有些索引使用率高,会被并保存到内存中。有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据,Frozenindices的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或分钟基本不的,eager_global_ordinals不适用于Frozen indices enable 是否创建倒排索引,可以对字段操作,也可以对索引操作。如果不创建索引,仍然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。PUT my_index{"mappings":{"enabled":false}} filedata 查询时内存数据结果,在首次使用当前字段聚合、排序或者在脚本中使用时,需要字段为filedata数据结构,并创建倒排索引保存到堆中 fileds 给filed创建多字段,用于不同目的(全文检索或者聚合分析索引排序) format 格式化 ignore_above 超长字段将被忽略 ignore_malformed 忽略类型错误 index_options 控制将哪些信息添加到反向索引中以进行搜索和突出显示,仅用于text字段 index_phrases 提升exact_value查询速度,但是要消耗更多磁盘空间 index_prefixes 前缀搜索。min_chars:前缀最小长度,> 0 ,默认为2(包含);max_charrs:前缀最大长度,< 20 ,默认为5(包含) meta 附加元数据 normalizer norms 是否禁用评分(在filter和聚合字段上应该禁用) null_value 为null值设置默认值 position_increment_gap proterties 处理mapping还可用于object的属性设置 search_analyzer 设置单独的查询分析器 similarity 为字段设置相关度算法,支持BM24、classic(TF-IDF)、Boolean store 设置字段是否仅查询 term_vector 运维参数
-
-
- 禁用元数据 好处 节省存储 坏处 不支持update、update_by_query和reindex API。 不支持高亮 不支持reindex、更改mapping分析器和版本升级 通过查看索引时使用的原始文档来调试查询或聚合的功能 将来有可能自动修复索引损坏 总结 如果只是为了节省磁盘,可以压缩索引比禁用_source更好 GET /product/_search { "_source": false, "query": { "match_all": {} } } 数据源过滤器 分类 Including:结果中返回哪些field Excluding:结果中不要返回哪些field,不返回的field不代表不能通过该字段进行检索,因为元数据不存在不代表所有不存在。 使用 在mapping中定义过滤[[Elasticsearch教程入门到精通#^d20b46]]:支持通配符,但不推荐,因为mapping不可变。 常用过滤规则 "_source":"false," 禁用 "_source":"obj.*", "_source":["obj1.*","obj2.*"], "_sourc":{"includes":["obj1.*","obj2.*"],"excludes":["*.description"]} mapping定义过滤 ^d20b46 PUT /product2/ { "mappings": { "_source": { "includes":[ "name", "price" ], "excludes":[ "desc", "tags" ] } } }
- 查询所有 GET /product/_search 带参数 GET /product/_search?q=name:xiaomi 分页 GET /prodect/_search?form=0&size=2&sort=price:asc 精准匹配 GET /product/_search?q=date:2021-06-01 _all搜索 GET /product/_search?q=2021-06-01
-
- 对于keyword类型是精准查询,对于text是先分析在查询 GET /product/_search { "query": { "match": { "date": "2021-06-01" } } }
- GET /product/_search { "query": { "match_all": {} } }
- select * from table wher a=xx and b=yyy GET /product/_search { "query": { "multi_match": { "query": "phone huangmenji", "fields": ["name","desc"] } } }
- GET /product/_search { "query": { "match_phrase": { "name": "xiaomi nfc" } } }
-
- 匹配和搜索词项完全相等的结果【注意搜索text会被分词,搜索keyword才能匹配上】 term和match_phrase区别 match_phrase 会将检索关键词分词,match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,同时默认必须都是连续性的【3个条件】 term不会将搜索词分词 term和keryword的区别 term是对于搜索词部分此 keyword是字段类型,是对于source data中的字段值不分词 GET /product/_search { "query": { "term": { "name":"xiaomi phone" } } } #match_phrase GET /product/_search { "query": { "match_phrase": { "name": "xiaomi phone" } } }
- 匹配和搜索词项列表中任意项匹配的结果,类似于MySql中的in语句【select * from table t where t.a in xxx 】 GET /product/_search { "query": { "terms": { "tags": [ "xingjiabi", "buka" ] } } }
- 范围查找 GET /product/_search { "query": { "range": { "price": { "gte": 399, "lte": 1000 } } } } # 注意时区的用法 GET /product/_search { "query": { "range": { "date": { "time_zone": "+08:00", "gte": "now-10y/y", "lte": "now/d" } } } }
- 性能比query好一点
- 可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值(filter和must_not不会计算评分)。
- must 必须满足子句(查询)必须出现在匹配的文档章,并将有助于得分。 filter 过滤器,不计算相关度分数,chche子句查询必须出现在匹配的文档中。 但是不像must查询的分数将会被忽略。Filter子句在filter上下文中执行,这意味着计分被忽略,并且子句将被考虑用于缓存。 should 可能满足or子句(查询)应该出现在匹配的文档中 must_not 必须不满足不计算相关度分数 子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被沪铝,并且子句被视为用于缓存。因此将返回素有文档的分数。 minimum_should_match: 参数指定shuld返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或filter子句,则默认值为1,否则默认值为0.
- GET product/_search { "_source": false, "query": { "bool": { "must": [ { "match": { "name": "xiaomi phone" } }, { "match": { "desc": "shouji zhong" } } ] } } }
- GET product/_search { "_source": false, "query": { "bool": { "filter": [ { "match": { "name": "xiaomi phone" } }, { "match": { "desc": "shouji zhong" } } ] } } }
- GET product/_search { "_source": false, "query": { "bool": { "must_not": [ { "match": { "name": "xiaome phon" } }, { "range": { "price": { "gte": 1000 } } } ] } } }
- GET product/_search { "query": { "bool": { "should": [ { "match_phrase": { "name": "xiaome phon" } }, { "range": { "price": { "gte": 4000 } } } ] } } } 组合 # filter和must的关系为and GET /product/_search { "query": { "bool": { "filter": [ { "range": { "price": { "gte": 1000 } } } ], "must": [ { "match": { "name": "xiaomi" } } ] } } }
- #later https://www.bilibili.com/video/BV1LY4y167n5?p=28&vd_source=c013484f4cbc43b024e86dcb9864399e 24min左右 # 注意should和filter/must的组合情况 # 没有minimum_should_match的话,默认为0条数据 GET /product/_search { "_source": false, "query": { "bool": { "filter": [ { "range": { "price": { "gte": 1000 } } } ], "should": [ { "match_phrase": { "name": "nfc phone" } }, { "match": { "name": "erji" } } ], "minimum_should_match": 1 } } } # 注意should和filter/must的组合情况 # 没有minimum_should_match的话,默认为0条数据 # bool查询可以组合嵌套 GET /product/_search { "_source": false, "query": { "bool": { "filter": [ { "range": { "price": { "gte": 1000 } } } ], "should": [ { "match_phrase": { "name": "nfc phone" } }, { "match": { "name": "erji" } }, { "bool": { "must": [ { "range": { "price": { "gte": 900, "lte": 5000 } } } ] } } ], "minimum_should_match": 2 } } }
-
- https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis.html
- 文档规范化,提高召回率 停用词 时态转换 大小写 同义词 语气词
- 分词前的预处理,过滤无用字符 HTML Strip Character Filter: httm_strip 参数: escaped_tags : 需要保留的html标签 DELETE cf_test_index PUT cf_test_index { "settings": { "analysis": { "char_filter":{ "my_char_filter":{ "type":"html_strip", "escaped_tags":["a"] } }, "analyzer": { "my_analyzer":{ "tokenizer":"keyword", "char_filter":"my_char_filter" } } } } } GET /cf_test_index/_analyze { "analyzer": "my_analyzer", "text": "<p>I'm so <a>happy</a>!</p>" } Mapping Character Filter: type mapping DELETE map_test_index PUT map_test_index { "settings": { "analysis": { "char_filter":{ "my_char_filter":{ "type":"mapping", "mappings":[ "滚 => *", "垃 => *", "圾 => *" ] } }, "analyzer": { "my_analyzer":{ "tokenizer":"keyword", "char_filter":"my_char_filter" } } } } } GET /map_test_index/_analyze { "analyzer": "my_analyzer", "text": "滚吧,垃圾!" } Pattern Replace Characteer Filter: type pattern_replace 注意正则表达式不要写错了 DELETE pattern_filter_test_index PUT pattern_filter_test_index { "settings": { "analysis": { "char_filter":{ "my_char_filter":{ "type":"pattern_replace", "pattern":"(\\d{3})\\d{4}(\\d{4})", //$1代表上面第一个()匹配项 "replacement":"$1****$2" } }, "analyzer": { "my_analyzer":{ "tokenizer":"keyword", "char_filter":["my_char_filter"] } } } } } GET /pattern_filter_test_index/_analyze { "analyzer": "my_analyzer", "text": "你得手机号是17611001200" }
- 停用词、时态转换、大小写转换、同义词转换、语气词处理等。比如:has=>have him=>he apples=>apple the/oh/a=> 干掉 同义词示例 https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-synonym-graph-tokenfilter.html DELETE my_synonym_index # 注意文件 # https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-synonym-graph-tokenfilter.html PUT my_synonym_index?pretty { "settings": { "analysis": { "filter": { "my_synonym": { "type": "synonym_graph", "synonyms_path": "analysis/synonym.txt" } }, "analyzer": { "my_analyzer": { "tokenizer": "ik_max_word", "filter": [ "my_synonym" ] } } } } } GET /my_synonym_index/_analyze { "text": ["daG"] , "analyzer": "my_analyzer" } emperinter@lover:/app/elasticsearch/analysis$ more synonym.txt 蒙丢丢,mengdiou => 蒙迪欧 大G => 奔驰G级 霸道 => 普拉多 daG => prodo
- GET /my_synonym_index/_analyze { "tokenizer": "ik_max_word", "text":"我爱北京天安门" } 场景分词器 standard analyzer: 默认分词器,中文支持的不理想,会逐字拆分 pattern tokenizer:以正则匹配分隔符,把文本拆分成若干词项。 simple pattern tokenizer: 以正则匹配词项,速度比pattern tokenizer快。 whitespace analyzer: 以空白符分隔
- char_filter: 内置或自定义字符过滤器 token_filter: 内置或自定义token filter tokenizer: 内置或自定义分词器 DELETE custom_analysis_test_index # 注意my_tokenizer 有个空格 PUT custom_analysis_test_index { "settings": { "analysis": { "char_filter": { "my_char_filter": { "type": "mapping", "mappings": [ "& => and", "| => or" ] }, "html_strip_char_filter":{ "type":"html_strip", "eacaped_tags":["a"] } }, "filter": { "my_stopword": { "type": "stop", "stop_words": [ "is", "in", "the", "a", "at", "for" ] } }, "tokenizer": { "my_tokenizer":{ "type":"pattern", "pattern":"[ ,.!?]" } }, "analyzer": { "my_analyzer": { "type": "custom", "char_filter": [ "my_char_filter", "html_strip_char_filter" ], "tokenizer":"my_tokenizer" } } } } } GET /custom_analysis_test_index/_analyze { "analyzer": "my_analyzer", "text":["What is ,<a>asdf . </a>ss in ? | & | is ! <p>in the a at for</p>"] }
-
- https://github.com/medcl/elasticsearch-analysis-ik 远程安装 elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip root@020ba19969e9:/usr/share/elasticsearch/bin# elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip -> Installing https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip -> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip [=================================================] 100%?? @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: plugin requires additional permissions @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ * java.net.SocketPermission * connect,resolve See https://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html for descriptions of what these permissions allow and the associated risks. Continue with installation? [y/N]y -> Installed analysis-ik -> Please restart Elasticsearch to activate any plugins installed
- IKAnalyzer.cfg.xml: IK 分词配置文件 主词库: main.dic 英文停用词:stopword.dic,不会建立在倒排索引重 特殊词库 quantificer.dic: 特殊词库:计量单位等 suffix.dic: 特殊词库: 后缀名 surname.dic: 特殊词库:百家姓 preposition:特殊词库:语气词 自定义词库 网络词汇、流行词、自造词等。
- #ik_max_word使用较多 GET /custom_analysis_test_index/_analyze { "analyzer": "ik_max_word", "text":"我爱中华人民共和国" } GET /custom_analysis_test_index/_analyze { "analyzer": "ik_smart", "text":"我爱中华人民共和国" }
- 防止重启影响生成
- https://github.com/medcl/elasticsearch-analysis-ik 更改ik配置文件 emperinter@lover:/app/elasticsearch/analysis-ik$ more IKAnalyzer.cfg.xml <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties> 优点 上手简单 缺点 词库管理不方便,要直接操作磁盘文件,检索页maf 文件读写没有专业的性能优化不好 多一层服务接口调用和网络传输
- 需要更改ES 源码,官方貌似并没有推荐过这种方式。 参考:https://juejin.cn/post/7093385981537026085
- GET /index_name/_search
{
"aggs": {
"<aggs_name>": {
"AGG_TYPE": {
"filed":"<filed_name>"
}
},
"<aggs_name2>": {
"AGG_TYPE": {
"filed":"<filed_name>"
}
}
}
}
-
- 分类,类似于Group By GET /product/_search { "size": 0, "aggs": { "aggs_tag": { "terms": { "field": "tags.keyword", "size": 30, "order": { "_count": "asc" } } } } }
- AVG平均值、Max最大值、Min最小值、Sum求和、Value Count 计数、Stats统计聚合、Top Hits聚合、cardinality基数(去重) # 统计最贵,最便宜和平均价格三个指标 GET /product/_search { "size": 0, "aggs": { "max_price": { "max": { "field": "price" } }, "min_price":{ "min": { "field": "price" } }, "avg_price":{ "avg": { "field": "price" } } } } GET /product/_search { "size": 0, "aggs": { "price_status": { "stats": { "field": "price" } } } } # 按照name去重的数量 GET /product/_search { "size": 0, "aggs": { "name_count": { "cardinality": { "field": "name.keyword" } } } }
- 对聚合的结果二次聚合 分类 父级 兄弟级 语法 buckets_path 注意buckets_path的第一个参数应该是和它平级的名称 # 管道聚合 # 统计平均价格最低的商品分类 # 先分类再计算平均价格,最后再计算最小值 GET /product/_search { "size": 0, "aggs": { "product_type": { "terms": { "field": "type.keyword", "size": 10 }, "aggs": { "product_avg_price": { "avg": { "field": "price" } } } }, "min_bucket":{ "min_bucket": { "buckets_path": "product_type>product_avg_price" } } } }
- 语法 注意嵌套级别 GET /index_name/_search { "size": 0, "aggs": { "<agg_name>": { "<AGG_TYPE>": { "field":"<field_name>" }, "aggs": { "<agg_name_child>": { "<AGG_TYPE>": { "field":"<field_name>" } } } } } } 示例 # 嵌套聚合 # 统计不同类型商品的不同级别的数量 GET /product/_search { "size": 0, "aggs": { "type": { "terms": { "field": "lv.keyword" }, "aggs": { "lv_agg": { "terms": { "field": "lv.keyword" } } } } } } # 按照lv分桶,输出每个桶的具体价格信息 GET /product/_search { "size": 0, "aggs": { "lv_price": { "terms": { "field": "lv.keyword" }, "aggs": { "price": { "stats": { "field": "price" } } } } } } # 统计不同类型商品,不同档次的价格信息 GET /product/_search { "size": 0, "aggs": { "product_type": { "terms": { "field": "type.keyword" }, "aggs": { "product_lv": { "terms": { "field": "lv.keyword" }, "aggs": { "product_price_status": { "stats": { "field": "price" } } } } } } } } # 统计不同类型商品,不同档次的价格信息 标签信息 # 注意aggs是可以多个参数的 GET /product/_search { "size": 0, "aggs": { "product_type": { "terms": { "field": "type.keyword" }, "aggs": { "product_lv": { "terms": { "field": "lv.keyword" }, "aggs": { "product_price_status": { "stats": { "field": "price" } }, "diff_tags":{ "terms": { "field": "tags.keyword" } } } } } } } } # 统计每个商品类型中 不同档次分类商品中 平均价格最大的档次 # 注意buckets_path的第一个参数应该是和它平级的名称 GET /product/_search { "size": 0, "aggs": { "diff_type": { "terms": { "field": "type.keyword" }, "aggs": { "diff_lv": { "terms": { "field": "lv.keyword" }, "aggs": { "avg_price": { "avg": { "field": "price" } } } }, "max_avg_price_lv":{ "max_bucket": { "buckets_path": "diff_lv>avg_price" } } } } } }
-
- GET /product/_search { "size": 10, "query": { "range": { "price": { "gte": 5000 } } }, "aggs": { "tag_bucket": { "terms": { "field": "tags.keyword" } } } } GET /product/_search { "query": { "bool": { "filter": { "range": { "price": { "gte": 5000 } } }, "boost": 1.2 } }, "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } } }
- GET /product/_search { "aggs": { "tags_bucket": { "terms": { "field": "tags.keyword" } } }, "post_filter": { "term": { "tags.keyword": "性价比" } } }
- ## 取消查询条件&&查询条件嵌套 GET /product/_search { "size": 10, "query": { "range": { "price": { "gte": 4000 } } }, "aggs": { "max_price": { "max": { "field": "price" } }, "min_price":{ "min": { "field": "price" } }, "avg_price":{ "avg": { "field": "price" } }, "all_avg_price":{ "global": {}, "aggs": { "avg_price": { "avg": { "field": "price" } } } } } } 复杂的用法 # multi_avg_price的filter何query的查询是产生了交集 GET /product/_search { "size": 10, "query": { "range": { "price": { "gte": 4000 } } }, "aggs": { "max_price": { "max": { "field": "price" } }, "min_price":{ "min": { "field": "price" } }, "avg_price":{ "avg": { "field": "price" } }, "all_avg_price":{ "global": {}, "aggs": { "avg_price": { "avg": { "field": "price" } } } }, "multi_avg_price":{ "filter": { "range":{ "price":{ "lte":4500 } } }, "aggs": { "avg_price": { "avg": { "field": "price" } } } } } }
- 排序方式 _doc _key _count 简单排序 GET /product/_search { "size": 0, "aggs": { "fisrt_sort": { "terms": { "field": "tags.keyword", "size": 30, "order": { "_count": "desc" } }, "aggs": { "second": { "terms": { "field": "lv.keyword", "order": { "_count": "asc" } } } } } } } 多层聚合排序 # 多层聚合 # 注意第一层order的用法 GET /product/_search { "size": 0, "aggs": { "type_avg_price": { "terms": { "field": "type.keyword", "order": { "aggs_stats>stats.min": "desc" } }, "aggs": { "aggs_stats": { "filter": { "terms": { "type.keyword": [ "耳机", "手机", "电视" ] } }, "aggs": { "stats": { "stats": { "field": "price" } } } } } } } } ^445511
-
- # missing: 空值的处理罗偶极,对字段的控制赋予默认值 GET /product/_search { "size": 0, "aggs": { "price_histogram": { "histogram": { "field": "price", "interval": 1000, "keyed": true, "min_doc_count": 1, "missing": 1999 } } } }
- 注意extended_bounds的用法 GET /product/_search { "size": 0, "aggs": { "my_date_histogram": { "date_histogram": { "field": "creattime", "calendar_interval": "month", "format": "yyyy-MM", "extended_bounds": { "min": "2020-01", "max": "2020-12" }, "order": { "_count": "desc" } } } } } auto_date_histogram GET /product/_search { "size": 0, "aggs": { "my_auto_histogram": { "auto_date_histogram": { "field": "creattime", "format": "yyyy-MM-dd", "buckets":180 } } } } ^73e926 累加和的情况 # my_cumulative_sum累加和/总计 GET /product/_search { "size": 0, "aggs": { "my_date_histogram": { "date_histogram": { "field": "creattime", "calendar_interval": "month", "format": "yyyy-MM", "extended_bounds": { "min": "2020-01", "max": "2020-12" }, "order": { "_count": "desc" } }, "aggs": { "sum_agg": { "sum": { "field": "price" } }, "my_cumulative_sum":{ "cumulative_sum": { "buckets_path": "sum_agg" } } } } } }
- percentiles 由百分比区间求数据 ## 百分位统计 GET /product/_search { "size": 0, "aggs": { "price_precentiles": { "percentiles": { "field": "price", "percents": [ 1, 5, 25, 50, 75, 95, 99 ] } } } } percentile_ranks 由数据求百分比区间 TDigest算法 GET /product/_search { "size": 0, "aggs": { "price_precentiles": { "percentile_ranks": { "field": "price", "values": [ 1000, 2000, 3000, 4000, 5000, 6000 ] } } } }
-
-
- ES 支持的专门用于复杂场景下支持自定义编程的强大的脚本功能。 ES支持的Scripts Groovy: ES1.4.x - 5.0 的默认脚本语言 painless: 专门用于ES的语言,用于内联和存储脚本,类似于Java,也有注释、关键字、类型、变量、函数等,是一种安全的脚本语言。 其它 expression: 每个文档的开销较低,表达式的作用更多,可以非常快速地执行,甚至比编写native脚本还是要更快,支持JavaScript语法的子集:单个表达式。缺点是只能访问数字、布尔值、日期和geo_point字段,存储的字段不可用。 mustache: 提供模板参数化查询 特点 优点 语法简单,学习成本低 灵活度高,可编程能力强 性能相较于其它脚本语言更高 安全性好 缺点 独立语言,虽然易学但仍需要单独学习 相较于DSL性能低 不适用于非复杂的业务场景。 语法 ## ES 脚本 ## 语法: ctx._source.<field-name> GET /product/_search/ { "query": { "term": { "_id": { "value": "3" } } } } POST /product/_update/3 { "script": { "source": "ctx._source.price-=1" } } POST /product/_update/3 { "script": { "source": "ctx._source.price-=ctx._version" } } # 简写 POST /product/_update/3 { "script": "ctx._source.price-=1" }
- 索引备份 POST _reindex { "source": { "index": "product" }, "dest": { "index": "product2" } } 新增/修改 # 新增/修改 POST /product2/_update/2 { "script": { "lang": "painless", "source": "ctx._source.tags.add('无线充电')" } } upsert= update+insert # upsert # 有则update无则insert POST product2/_update/15 { "script": { "lang": "painless", "source": "ctx._source.price+=100" }, "upsert": { "name":"小米手机10", "desc":"充电快!", "price":2000 } } 删除 # delete POST /product2/_update/11 { "script": { "lang": "painless", "source": "ctx.op='delete'" } } 查询 painless expression # painlesss查询 POST /product2/_search { "script_fields": { "my_price": { "script": { "lang": "expression", "source": "doc['price'] * 0.9" } } } } # expression 查询 POST /product2/_search { "script_fields": { "my_price": { "script": { "lang": "painless", "source": "doc['price'].value * 0.9" } } } }
- 减少重复编译脚本过程 默认缓存是100MB 单参数 # 默认缓存是100M POST product2/_update/6 { "script": { "lang": "painless", "source": "ctx._source.tags.add(params.tag_name)", "params": { "tag_name":"无线秒充" } } } 多个参数 GET /product2/_search { "script_fields": { "original_price":{ "script":{ "lang": "painless", "source": "doc['price'].value" } } , "discount_price": { "script": { "lang": "painless", "source": "[doc['price'].value * params.discount_8,doc['price'].value * params.discount_7,doc['price'].value * params.discount_6,doc['price'].value * params.discount_5]", "params": { "discount_8":0.8, "discount_7":0.7, "discount_6":0.6, "discount_5":0.5 } } } } }
- _scriprts/{模板id} 创建 # 创建 # 写入缓存中 POST _scripts/calculate_discount { "script": { "lang": "painless", "source": "doc.price.value * params.discount" } } 查看 # 查看 GET _scripts/calculate_discount 使用 # 使用 GET product2/_search { "script_fields": { "original_price": { "script": { "lang": "painless", "source": "doc['price'].value" } }, "discount_fields": { "script": { "id": "calculate_discount", "params": { "discount": 0.8 } } } } }
- simple case POST product2/_update/1 { "script": { "lang": "painless", "source": """ ctx._source.tags.add(params.tag_name); ctx._source.price-=100; """, "params": { "tag_name":"无线秒充" } } } 复杂 # 正则 # like %小米% # 有则更改 # 没有result返回noop POST product2/_update/3 { "script": { "lang": "painless", "source": """ if(ctx._source.name ==~ /[\s\S]*小米[\s\S]*/){ ctx._source.name+="***|" }else{ ctx.op = "noop" } """, "params": { "tag_name":"无线秒充" } } } ## 日期 POST product2/_update/1 { "script": { "lang": "painless", "source": """ if(ctx._source.creattime ==~ /\d{4}-\d{2}-\d{2}[\s\S]*/){ ctx._source.name+="***|" }else{ ctx.op = "noop" } """ } } # 统计所有价格大于5000的tag数量,不考虑重复情况 # 注意其中的循环统计用法 GET /product2/_search { "query": { "constant_score": { "filter": { "range": { "price": { "gte": 5000 } } }, "boost": 1.2 } }, "aggs": { "taga_agg": { "sum": { "script": { "lang": "painless", "source": """ int total = 0; for(int i = 0;i < doc['tags.keyword'].length;i++){ total++ } return total """ } } } } }
- 一些早期版本是默认禁用正则的,需要手动开启 script.painless.regex.enables : true 数据 PUT test_index/_bulk?refresh {"index":{"_id":1}} {"ajbh":"12345","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三","NL":"30","SF":"男"},{"XM":"李四","NL":"31","SF":"男"},{"XM":"王五","NL":"30","SF":"女"},{"XM":"赵六","NL":"23","SF":"男"}]} {"index":{"_id":2}} {"ajbh":"563245","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三2","NL":"30","SF":"男"},{"XM":"李四2","NL":"31","SF":"男"},{"XM":"王五2","NL":"30","SF":"女"},{"XM":"赵六2","NL":"23","SF":"男"}]} {"index":{"_id":3}} {"ajbh":"12345","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三3","NL":"30","SF":"男"},{"XM":"李四3","NL":"31","SF":"男"},{"XM":"王五3","NL":"30","SF":"女"},{"XM":"赵六3","NL":"23","SF":"男"}]} 复杂类似错误用法 # object nested # 遇到复杂类型是不能用doc # doc['field'].value 只能用于简单类型 # params['_source']['field'] GET /test_index/_search { "aggs": { "sum_person": { "sum": { "script": { "lang": "painless", "source": """ int total = 0; for (int i = 0;i < doc['jsbax_sjjh2_xz_ryjbxx_cleaning'].length;i++){ if(doc['jsbax_sjjh2_xz_ryjbxx_cleaning'][i]['SF'] == '男'){ total ++ } } return total; """ } } } } } 复杂类型正确用法 GET /test_index/_search { "aggs": { "sum_person": { "sum": { "script": { "lang": "painless", "source": """ int total = 0; for (int i = 0;i < params['_source']['jsbax_sjjh2_xz_ryjbxx_cleaning'].length;i++){ if(params['_source']['jsbax_sjjh2_xz_ryjbxx_cleaning'][i]['SF'] == '男'){ total ++ } } return total; """ } } } } }
-
- 复杂 GET /_mget { "docs":[ { "_index":"product", "_id":2 }, { "_index":"product", "_id":3 } ] } easy GET product/_mget { "ids":[ 2, 3, 4] } 指定字段 GET /_mget { "docs": [ { "_index": "product", "_id": 2, "_source": [ "name", "price" ] }, { "_index": "product", "_id": 3, "_source":{ "exclude":[ "lv", "type" ] } } ] }
-
- PUT /test_index/_doc/1/_create { "test_field":"test", "test_title":"title" } PUT /test_index/_create/3 { "test_field":"test", "test_title":"title" } 自动生成id POST /test_index/_doc { "test_field":"test", "test_title":"title" }
- 只是标记成删除了 DELETE /test_index/_doc/3
- PUT /test_index/_doc/oru0oIIBwVhBj7hhLYLT { "test_field": "test 1", "test_title": "title 1" } POST /test_index/_update/oru0oIIBwVhBj7hhLYLT/ { "doc": { "test_field": "test 3", "test_title": "title 3" } }
- 可以是创建(不存在),也可以是全量替换(已存在) PUT /test_index/_doc/oru0oIIBwVhBj7hhLYLT?op_type=index { "test_field": "test 2", "test_title": "title 2" } PUT /test_index/_doc/5?op_type=index { "test_field": "test 2", "test_title": "title ", "test_name": "test" } ?filter_path=items.*.error > 只输出错误信息,适用于批量操作数据量较大的情况下使用。 PUT /test_index/_create/3?filter_path=items.*.error { "test_field":"test", "test_title":"title" }
- 工具 格式 删除没有元数据,当数据量大时,注意使用?filter_path=items.*.error #POST /_bulk POST /<index_name>/_bulk {"action":{"metadata"}} {"data"} POST _bulk {"delete":{"_index":"product","_id":2}} {"create":{"_index":"product","_id":2}} {"name":"_bulk create"} {"update":{"_index":"product","_id":4}} {"doc":{"name":"_bulk update 2"}} {"delete":{"_index":"product","_id":1000}} {"create":{"_index":"product","_id":2}} {"name":"_bulk create"} # 只把错误信息显示出来 POST _bulk?filter_path=items.*.error {"delete":{"_index":"product","_id":2}} {"create":{"_index":"product","_id":2}} {"name":"_bulk create"} {"update":{"_index":"product","_id":4}} {"doc":{"name":"_bulk update 2"}} {"delete":{"_index":"product","_id":1000}} {"create":{"_index":"product","_id":2}} {"name":"_bulk create"} 好处 不消耗额外内存 坏处 可读性查
-
- 概念 以xx开头的搜索,不计算相关度评分 注意 前缀搜索匹配的是term(倒排索引后的词项),而不是field 注意词的拆分 如需搜索请配置analyzer的ik_max_word 前缀搜索性能很差 前缀搜索没有缓存 前缀搜索尽可能把前缀长度设置的更长 语法 GET <index_name>/_search { "query":{ "prefix":{ "<field>":{ "value":"<word_prefix>" } } } } index_prefixes: 默认 "min_chars":2,"max_chars":5 test case GET /my_index/_search { "query": { "prefix": { "text": { "value": "城管" } } } } 配置ik_max_word方便搜索 index_prefiex在索引的基础上(词项)再索引,加快前缀搜索的效率。但占用大量存储空间,不太好。 # index_prefiex在索引的基础上再索引,加快前缀搜索的效率 # eg: # elasticsearch stack # elasticsearch search # el # ela PUT my_index { "mappings": { "properties": { "text": { "analyzer": "ik_max_word", "type": "text", "index_prefixes":{ "min_chars":2, "max_chars":3 }, "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }
- 通配符运算符是匹配一个或多个字符的占位符。例如,* 通配符运算发匹配0个或多个字符。你可以将通配符与其它字符结合使用以创建通配符模式。 注意 通配符也匹配的是term,而不是field。 注意exact_value匹配时的特殊情况 语法 GET <index_name>/_search { "query":{ "wildcard":{ "<field>":{ "value":"<word_with_wildcard>" } } } }
- regexp查询的性能可以根据正则表达式而有所不同,为了提高性能,应避免使用统配符模式,如.或.?+未经前缀或后缀 语法 GET <index_name>/_search { "query":{ "regexp":{ "<field>":{ "value":"<reegexp>", "flags":"ALL" } } } } flags flags 说明 例子 ALL 启用所有可选操作符。 COMPLEMENT 启用~操作符,可以使用~对下面最短的模式进行否定 a~bc # matches 'adc' and 'aec' but not 'abc' INTERVAL 启用<>操作符,可以使用<>匹配数值范围 foo # matches 'foo1','foo2'...'foo99','foo100' ; fooo # matches 'foo01','foo02'....,'foo99','foo100' INTERSECTION 启用&操作符,它充当AND操作符。如果左边和右边的模式都匹配,则匹配成功。 aaa.+&.+bbb # matches aaabbb ANYSTRING 启用@操作符,你可以使用@来匹配任何整个字符串。你可以将@操作符与&和~操作符组合起来,创造一个"everything except"逻辑 @&~(abc.+) # matches everything except terms beginning with 'abc' test case GET product_en/_search { "query": { "regexp": { "title": "[\\s\\S]*nfc[\\s\\S]*" } } } GET product_en/_search { "query": { "regexp": { "title": { "value": "zh~dng", "flags": "COMPLEMENT" } } } } GET /product_en/_search { "query": { "regexp": { "tags.keyword": { "value": ".*<2-3>.*", "flags": "INTERVAL" } } } }
- 混淆字符 box > fox ; 缺少字符 black > lack ;多出字符 sic > sic ;颠倒词序 act > cat 语法 GET <index_name>/_search { "query":{ "fuzzy":{ "<field>":{ "value":"<keyword>" } } } } 参数 value:必须,关键字 fuzziness: 编辑距离,(0,1,2)并非越大越好,召回率高但结果不准确。 两段文本之间的Damerau-Levenshtein距离是使一个字符串与另一个字符串匹配所需的插入、删除、替换和调换的数量 距离公式: Levenshtein是lucene的 es改进版:Damerau-Levenshtein. axe=>aex Levenshtein=2 Damerau-Levenshtein=1 transpositions: (可选,布尔值)指示编辑是否包括两个相邻字符的变位(ab→ba),默认为true test case GET /product_en/_search { "query": { "fuzzy": { "desc":"quangengneng" } } } match也可以用fuzziness,但match是分词的,fuzzy是不分词的。 GET /product_en/_search { "query": { "match": { "desc":{ "query": "quangongneng", "fuzziness": 1 } } } }
- match_phrase: match_phrase会分词 被检索字段必须包含match_phrase中的所有词项并且顺序必须是相同的 被检索字段包含的match_phrase中的词项之间不能有其他词项【即查询字段应该在查询结果中(检索字段)是连续的】 match_phrase_prefix与match_phrase相同,但是它多了一个特性就是它允许在文本的最后一个词项(term)上的前缀匹配,如果是一个单词,比如a,它会匹配文 档字段所有以a开头的文档如果是一个短语,比如"this is ma",他会先在倒排索引中做以ma做前缀搜索,然后在匹配到的doc中做match_phrase查询(网上有的说是先match_phrase,然后再进行前级搜索,是不对的) 参数 analyzer 指定何种分析器来对该短语进行分词处理 max_expansions 限制匹配的最大词项 boost 用于设置该查询的权重 slop 允许短语间的词项(term)间隔: slop 参数告诉 match_phrase 查询词条相隔多运时仍然能将文档视为匹配 什么是相隔多远?意思是说为了让查询和 文档匹配你需要移动词条多少次 原理解析:https://www.elastic.co/cn/blog/found-fuzzy-search=performance-considerations GET /product_en/_search { "query": { "match_phrase_prefix": { "desc": { "query": "shouji zhong d", "max_expansions": 1 } } } } # 注意slop的理解 GET /product_en/_search { "query": { "match_phrase_prefix": { "desc": { "query": "zhong hongzhaji", "max_expansions": 50, "slop":1 } } } }
- 性能比其它更好,但更占用磁盘空间 ngram # ngram 和 edge-ngram # tokenizer GET _analyze { "tokenizer": "ngram", "text": "reba always loves me" } # min_gram = 1 "max_gram":2 # token filter 词项过滤器 GET _analyze { "tokenizer": "standard", "filter": ["ngram"], "text": "reba always loves me" } # min_gram = 1 "max_gram": 1 # r a l m # min_gram = 1 "max_gram": 2 # r a l m # re al lo me # min_gram = 2 "max_gram": 3 # re al lo mee # reb alw lov me PUT ngram_index { "settings": { "analysis": { "filter": { "2_3_ngram":{ "type":"ngram", "min_gram":2, "max_gram":3 } }, "analyzer": { "my_ngram":{ "type":"custom", "tokenizer":"standard", "filter":["2_3_ngram"] } } } }, "mappings": { "properties": { "text":{ "type": "text", "analyzer": "my_ngram", "search_analyzer": "standard" } } } } GET ngram_index/_mapping POST /ngram_index/_bulk { "index": { "_id": "1"} } {"text": "my english" } { "index": { "_id": "2"}} {"text": "my english is good" } { "index": { "_id": "3"} } {"text": "my chinese is good" } { "index": { "_id": "4"}} {"text": "my japanese is nice" } { "index": { "_id": "5"} } {"text": "my disk is full" } GET ngram_index/_search GET ngram_index/_mapping # 因为配置了2-3的ngram所以能够搜索到 GET ngram_index/_search { "query": { "match_phrase": { "text": "my eng is goo" } } } GET ngram_index/_search { "query": { "match_phrase": { "text": "my en is goo" } } } edge ngram DELETE edge_ngram_index GET /_analyze { "tokenizer": "standard", "filter": ["edge_ngram"], "text": "reba always loves me" } PUT edge_ngram_index { "settings": { "analysis": { "filter": { "edge_gram":{ "type":"edge_ngram", "min_gram":2, "max_gram":3 } }, "analyzer": { "my_edge_gram":{ "type":"custom", "tokenizer":"standard", "filter":["edge_gram"] } } } }, "mappings": { "properties": { "text":{ "type": "text", "analyzer": "my_edge_gram", "search_analyzer": "standard" } } } } POST /edge_ngram_index/_bulk { "index": { "_id": "1"} } {"text": "my english" } { "index": { "_id": "2"}} {"text": "my english is good" } { "index": { "_id": "3"} } {"text": "my chinese is good" } { "index": { "_id": "4"}} {"text": "my japanese is nice" } { "index": { "_id": "5"} } {"text": "my disk is full" } GET edge_ngram_index/_search { "query": { "match_phrase": { "text": "my en is goo" } } }
- 搜索一般都会要求具有“搜索推荐“或者叫"按索补全”的功能,即在用户输入提索的过程中,进行自动补全或者纠错以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验,这就是Suggest.
- term suggester正如其名只基于tokenizer之后的单个term去匹配建议词(针对单独term的搜索推荐),并不会考虑多个term之间的关系 语法 POST <index_name>/_search { "suggest":{ "<suggest_name>": { "text":"<search_content>", "term" { "suggest_mode": "<suggest mode>" "field":"<field_name>" } } } } Options: text: 用户搜索的文本 field要从哪个字段选取推荐数据 analyzer使用哪种分词器: size每个建议返回的最大结果数 sort:如何按照提示词項排序,参数值只可以是以下两个枚举: score:分数>词频>词填本身 frequency: 词频>分数>词本身 suggest_mode搜索推荐的推荐模式参数值亦是枚举: missing: 默认值。仅为不在索引中的词项生成建议词 popular: 仅返回与搜索词文档词频文档词频更高的建议词 always: 根据建议文本中的词项推荐任何匹配的建议词 max_edits:可以根据具有最大偏移量距离候选建议以便认为是建议。只能是1-2之间的值,其它任何值都将导致xxx prefix_length:前缀匹配的时候,必须满足的最少字符 min_word_length: 最少包含的单词数量 min_doc_freq: 最少的文档频率 max_term_freq: 最大词频率 test case DELETE news POST _bulk {"index":{"_index":"news","_id":1}} {"title":"baoqiang bought a new hat with the same color of this font, which is very beautiful baoqiangba baoqiangda baoqiangdada baoqian baoqia"} {"index":{"_index":"news","_id":2}} {"title":"baoqiangge gave birth to two children, one is upstairs, one is downstairs baoqiangba baoqiangda baoqiangdada baoqian baoqia"} {"index":{"_index":"news","_id":3}} {"title":"booqiangge 's money was rolled away baoqiangba baoqiangda baoqiangdada baoqian baoqia"} {"index":{"_index":"news","_id":4}} {"title":"baoqiangda baoqiangda baoqiangda baoqiangda baoqiangda baoqian baoqia"} GET news/_mapping # baoqing是故意输错的 # 返回结果的freq是指文档的个数 POST news/_search { "suggest": { "my-suggestion": { "text": "baoqing baoqiang", "term": { "suggest_mode": "popular", "field": "title", "min_doc_freq":3 } } } }
- 在term suggester的基础上考虑多个term之间的关系,比如哦是否同时在同一个索引原文中,相邻程度以及词频等等。 test case #phrase suggester DELETE test PUT test { "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 0, "analysis": { "analyzer": { "trigram": { "type": "custom", "tokenizer": "standard", "filter": [ "lowercase", "shingle" ] } }, "filter": { "shingle":{ "type": "shingle", "min shingle_size": 2, "max_shingle_size": 3 } } } } }, "mappings": { "properties": { "title":{ "type": "text", "fields": { "trigram":{ "type":"text", "analyzer":"trigram" } } } } } } POST test/_bulk {"index":{"_id":1}} {"title":"lucene and elasticsearch"} {"index":{"_id":2}} {"title":"lucene and elasticsearhc"} {"index":{"_id":3}} {"title":"luceen and elasticsearch"} GET test/_analyze { "analyzer": "standard", "text": "lucene and elasticsearch" } GET test/_search { "suggest": { "text": "Luceen and elasticsearhc", "simple_phrase": { "phrase": { "field": "title.trigram", //可信度 "confidence":0, "max_errors": 2, "direct_generator": [ { "field": "title.trigram", "suggest_mode": "always" } ], "highlight":{ "pre_tag":"<em>", "post_tag":"</em>" } } } } }
- 基于内存而非索引,性能强悍 / 需要结合特定的completion类型/只适合前缀 自动补全,自动完成,支持三种查询【前缀查询(prefix)模糊查询(fuzzy) 正则表达式查询(regex)】,主要针对的应用场 景就是"Auto Completion", 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响 应速度要求比较苛刻,因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起 存放,对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快,但是FST只能用于前缀查找,这也是Completion Suggester的用 限所在。 completion:函的一种特有类型,专门为suggest提供,基于内存,性能很高。 prefix query:基于前缀查询的搜索提示,是最常用的一种搜索推荐查询。 prefix:客户端搜索词 field:建议词字段 size: 需要返回的建议词数量(默认5) skip_duplicates: 是否过滤掉重复建议,默认false fuzzy query fuzziness: 允许的偏移量,默认auto transpositions: 如果设置为true,则换位计为一次更改而不是两次更改,默认为true。 min_length:返回模糊建议之前的最小输入长度,默认3 prefix_length:输入的最小长度(不检查模糊替代项)默认为1 unicode_aware:如果为true,则所有度量(如模糊编辑距离,换位和长度)均以Unicode代码点而不是以字节为单位,这比原始字节略慢,因此默 认情况下将其设置为false。 regex query:可以用正则表示前缀,不建议使用 test case DELETE suggest_carinfo PUT suggest_carinfo { "mappings": { "properties": { "title":{ "type": "text", "analyzer": "ik_max_word", "fields": { "suggest":{ "type":"completion", "analyzer":"ik_max_word" } } }, "content":{ "type": "text", "analyzer": "ik_max_word" } } } } POST _bulk {"index":{"_index": "suggest_carinfo","_id":1}} {"title":"宝马X5 两万公里准新车","content":"这里是宝马X5图文描述"} {"index":{"_index": "suggest_carinfo","_id":2}} {"title":"宝马5系","content":"这里是奥迪A6图文描述"} {"index":{"_index":"suggest_carinfo","_id":3}} {"title":"宝马3系","content":"这里是奔驰图文描述"} {"index":{"_index":"suggest_carinfo","_id":4}} {"title":"奥迪Q5 两万公里准新车","content":"这里是宝马X5图文描述"} {"index":{"_index": "suggest_carinfo","_id":5}} {"title":"奥迪A6 无敌车况","content":"这里是奥迪A6图文描述"} {"index":{"_index": "suggest_carinfo","_id":6}} {"title":"奥迪双钻","content":"这里是奔驰图文描述"} {"index":{"_index": "suggest_carinfo","_id":7}} {"title":"奔驰AMG 两万公里准新车","content":"这里是宝马X5图文描述"} {"index":{"_index": "suggest_carinfo","_id":8}} {"title":"奔驰大G 无敌车况","content":"这里是奥迪A6图文描述"} {"index":{"_index":"suggest_carinfo","_id":9}} {"title":"奔驰C260","content":"这里是奔驰图文描述"} {"index":{"_index": "suggest_carinfo", "_id":10}} {"title":"nir奔驰C260","content":"这里是奔驰图文描述"} # 语法 GET suggest_carinfo/_search { "suggest": { "car_suggest": { "prefix":"奥迪", "completion":{ "field":"title.suggest" } } } } # fuzzy GET suggest_carinfo/_search { "suggest": { "car_suggest": { "prefix":"宝马5系", "completion":{ "field":"title.suggest", "skip_duplicates":true, "fuzzy":{ "fuzziness":2 } } } } } #正则 GET suggest_carinfo/_search { "suggest": { "car_suggest": { "regex":"nir", "completion":{ "field":"title.suggest", "size":10 } } } }
- context suggester: 完成建议者会考虑索引中的所有文档,但是通常希望提供由某些条件过滤和/或增强的建议。 test case #定义一个名为place_type 的类别上下文,其中类别必须与建议一起发送。 #定义一个名为 location 的地理上下文,类别必须与建议一起发送 DELETE place PUT place { "mappings": { "properties": { "suggest": { "type": "completion", "contexts": [ { "name": "place_type", "type": "category" }, { "name": "location", "type": "geo", "precision": 4 } ] } } } } GET place/_mapping PUT place/_doc/1 { "suggest": { "input": [ "timmy's", "starbucks", "dunkin donuts" ], "contexts": { "place_type": [ "cafe", "food" ] } } } PUT place/_doc/2 { "suggest": { "input": [ "monkey", "timmy's", "Lamborghini" ], "contexts": { "place_type": [ "money" ] } } } GET place/_search POST place/_search?pretty { "suggest": { "place_suggestions": { "prefix":"sta", "completion":{ "field":"suggest", "size":10, "contexts":{ "place_type":["cafe","restaurants"] } } } } } # boost提升权重用法 POST place/_search?pretty { "suggest": { "place_suggestions": { "prefix": "sta", "completion": { "field": "suggest", "size": 10, "contexts": { "place_type": [ { "context": "cafe" }, { "context": "money", "boost": 2 } ] } } } } } PUT place/_doc/3 { "suggest": { "input": "timmy's", "contexts": { "location": [ { "lat": 43.6624803, "lon": -79.3863353 }, { "lat": 43.6624718, "lon": -79.3878227 } ] } } } GET place/_search { "suggest": { "place_suggestion": { "prefix": "tim", "completion": { "field": "suggest", "size": 10, "contexts": { "location":{ "lat":43.662, "lon":-79.380 } } } } } } #定义一个名为 place type 的类别上下文,其中类别是从 cat字段中读取的。 #定义一个名为 location 的地理上下文,其中的类别是从 loc字段中读取的。 DELETE place_path_category PUT place_path_category { "mappings": { "properties": { "suggest": { "type": "completion", "contexts": [ { "name": "place_type", "type": "category", "path": "cat" }, { "name": "location", "type": "geo", "precision": 4, "path": "loc" } ] }, "loc": { "type": "geo_point" } } } } #如果映射有路径,那么以下索引请求就足以添加类别 #这些建议将与咖啡馆和食品类别另一个字段并且类别被明确索引,则建议将使用两组类别进行索引 PUT place_path_category/_doc/1 { "suggest": [ "timmy's", "starbucks", "dunkin donuts" ], "cat": [ "cafe", "food" ] } POST place_path_category/_search?pretty { "suggest": { "place_suggestion": { "prefix": "tim", "completion": { "field": "suggest", "context": { "place_type": [ { "context": "cafe" } ] } } } } }
- 【马士兵教育】2022版Elasticsearch教程入门到精通
- 搜索引擎
- 全文搜索引擎
- 自然语言处理,百度等等
- 垂直搜索引擎
- 有明确搜索目的
- 搜索引擎应该具备的要求
- 查询快
- 高效的压缩算法
- 快速的编解码速度
- 结果准确
- 结果丰富
- 面对海量数据,如何实现高效查询?
- 索引
- 全文搜索引擎
- 自然语言处理,百度等等
- 垂直搜索引擎
- 有明确搜索目的
- 查询快
- 高效的压缩算法
- 快速的编解码速度
- 结果准确
- 结果丰富
- 索引

- MySQL索引结构
- B Trees
- B+Trees
- MySQL索引能解决大数据检索得问题吗?
- 索引往往字段很长,如果使用B+Trees,树可能很深,IO很可怕。
- 索引可能会失效
- 精准度差
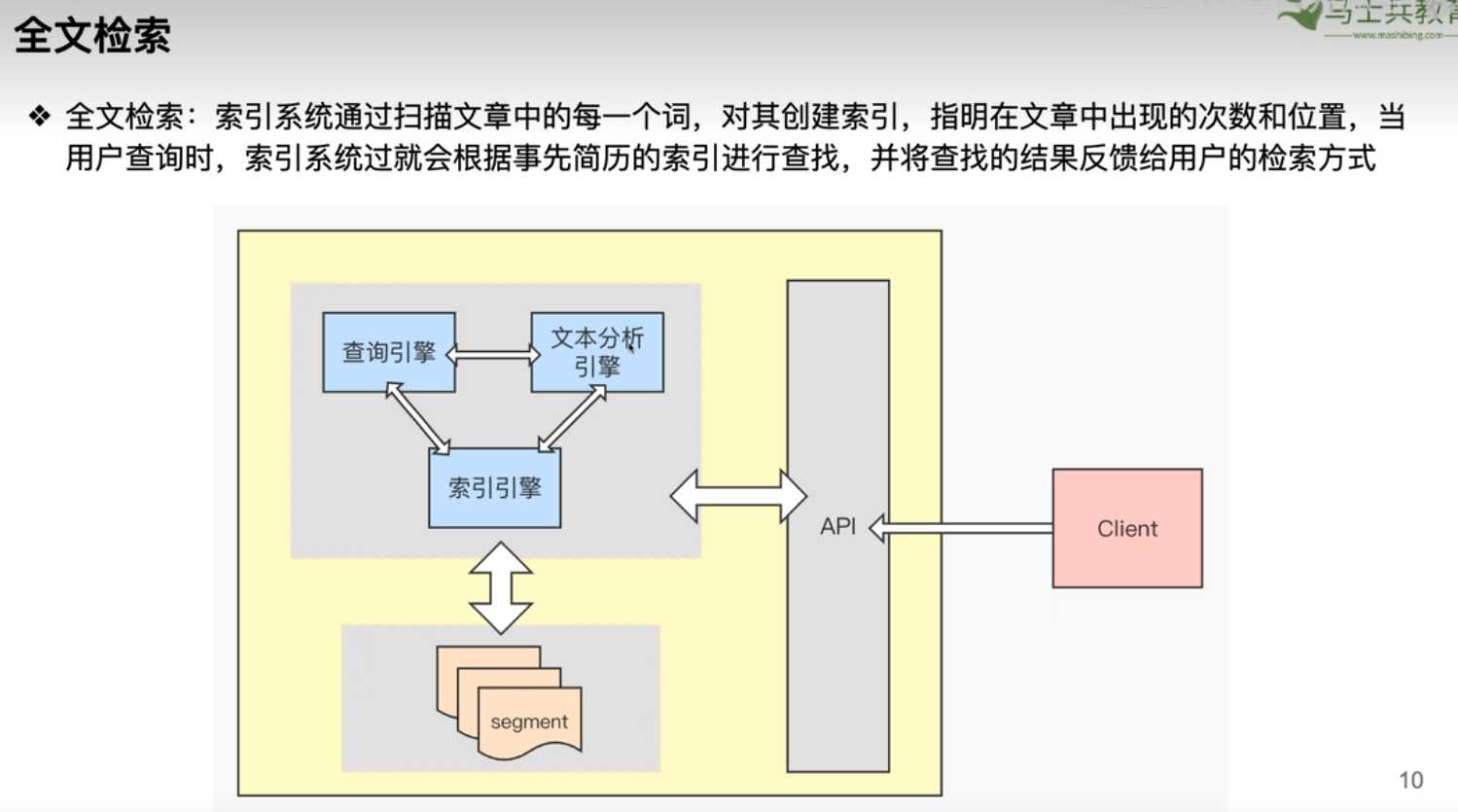
- 成熟的全文检索库,由JAVA编写
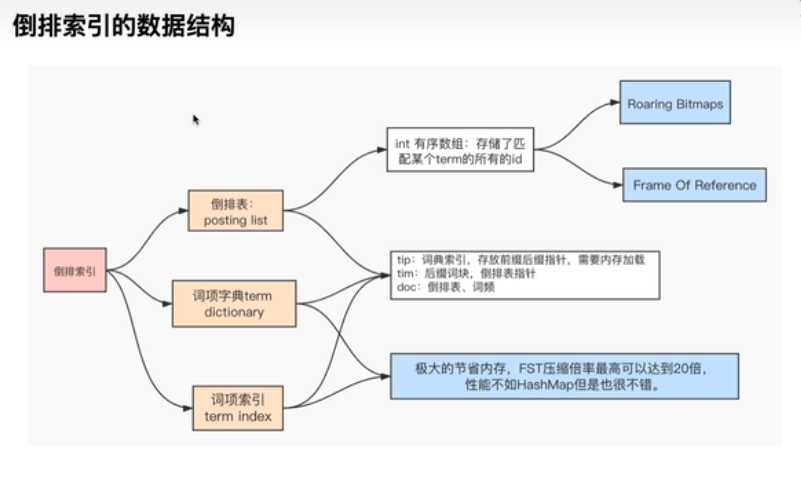
- 倒排表的压缩算法
- FOR : Framee of Reference
- RBM : RoaringBitMap
- 词项索引的检索原理
- FST : Finit state Transducers
- FOR : Framee of Reference
- RBM : RoaringBitMap
- FST : Finit state Transducers
_doc 8.x版本已废弃
基于REST风格的API
- 创建索引
PUT /index?pretty
- 查询索引
GET _cat/indices?v
- 删除索引
DELETE /index?pretty
- 插入数据
PUT /index/_doc/id
{
JSON 数据
}
- 替换
- 全量替换
- 指定字段更新
PUT /product/_doc/1
{
"price":3999
}
POST /product/_update/1
{
"doc": {
"price":5999
}
}
- 删除数据
DELETE /index/type/id
基于REST风格的API
PUT /index?pretty
GET _cat/indices?v
DELETE /index?pretty
PUT /index/_doc/id
{
JSON 数据
}
- 全量替换
- 指定字段更新
PUT /product/_doc/1
{
"price":3999
}
POST /product/_update/1
{
"doc": {
"price":5999
}
}
DELETE /index/type/id
- 概念
- 定义文档及其包含的字段的存储和索引方式的过程,类似于"表结构"
- 映射方式
- dynamic mapping(动态/自动映射)
- expllcit mapping(静态/手工/显示映射)
- 数据类型
- 参数
- 定义文档及其包含的字段的存储和索引方式的过程,类似于"表结构"
- dynamic mapping(动态/自动映射)
- expllcit mapping(静态/手工/显示映射)
GET /index/_mapping
GET /index/_mapping
- 数字类型
- long
- integer
- short
- byte
- double
- float
- half_float
- scaled_float
- unsigned_long
- Keywords:(关键词字段常用于排序、汇总和term查询)
- keyword:适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能通过精确值(exact value)搜索到。id应该用可以word
- constant_keyword : 始终包含相同值的关键词字段
- wildcard: 可针对于类似grep的通配符查询优化日志行和类似的关键字值。
- Dates(时间类型)
- date
- date_nannos
- alias
- 为现有字段设置别名
- binary
- 二进制
- range:区间类型
- integer_range
- float_range
- long_range
- double_range
- date_range
- text:
- 该字段适用于全文搜索的
- 字段内容会被分析
- 不用于排序,很少用于聚合
- long
- integer
- short
- byte
- double
- float
- half_float
- scaled_float
- unsigned_long
- keyword:适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能通过精确值(exact value)搜索到。id应该用可以word
- constant_keyword : 始终包含相同值的关键词字段
- wildcard: 可针对于类似grep的通配符查询优化日志行和类似的关键字值。
- date
- date_nannos
- 为现有字段设置别名
- 二进制
- integer_range
- float_range
- long_range
- double_range
- date_range
- 该字段适用于全文搜索的
- 字段内容会被分析
- 不用于排序,很少用于聚合
- object
- 适用于单个JSON对象
- nested
- 适用于JSON对象数组
- flattened
- 允许将整个JSON对象索引为单个字段
- 适用于单个JSON对象
- 适用于JSON对象数组
- 允许将整个JSON对象索引为单个字段
- geo-point: 经纬度积分
- geo-shape:用于多边形等复杂形状
- point:笛卡尔坐标点
- shape: 笛卡尔任意几何图形
- IP地址:IPV4/6
- compietion : 提供自动完成建议
- token_count : 计算字符串中令牌的数量
- murmur3 : 在索引时计算值的哈希并将其存储在索引中
- annotated-text : 索引包含特殊标记的文本(通常用于标识命名实体)
- precolator:接受来自query-dsl的查询
- join:为同一索引内的文档定义父/子关系
- rank_features: 记录数字功能以提高查询时的点击率
- dense_vector: 记录浮点值的密集向量
- sparse_vector: 记录浮点值的稀疏向量
- search-as-you-type: 争对查询优化的文本字段,以实现按需输入的完成
- histogram: 用于百分位数聚合的预聚合数值
- constant_keyword: keyword 当前文档都具有相同值时的情况的专业化
- 在ElasticSearch中,数组不需要专用的字段数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的值必需具有相同的数据类型。
- date_nanos: date_plus 纳秒
- features:
| JSON type | 域 type |
|---|---|
| 布尔型: true 或者 false | boolean |
| 整数: 123 | long |
| 浮点数: 123.45 | double |
| 字符串,有效日期: 2014-09-15 | date |
| 字符串: foo bar | 如果不是数字和字符串类型,会被映射为text和keyword类型 |
| 对象 | object |
| 数组 | 取决于数组中的第一个有效值的数据类型 |
- 其它类型必须手动映射
# 添加
PUT /index_name
{
"mappings": {
"properties": {
"date":{
"type":"date"
},
"name":{
"type":"text",
"analyzer": "english"
},
"user_id":{
"type":"long"
}
}
}
}
# 修改
POST /index_name
{
"mappints":{
"properties":
{
"name":{
"type":"keyword"
}
}
}
}
# 添加
PUT /index_name
{
"mappings": {
"properties": {
"date":{
"type":"date"
},
"name":{
"type":"text",
"analyzer": "english"
},
"user_id":{
"type":"long"
}
}
}
}
# 修改
POST /index_name
{
"mappints":{
"properties":
{
"name":{
"type":"keyword"
}
}
}
}
| 参数 | 说明 |
|---|---|
index |
是否创建该字段的倒排索引,默认为true。如果不创建索引,该字段不会通过索引被搜索到,但仍然会在source元数据中展示 |
analyzer |
指定分析器(character filter、tokenizer、token filters) |
boost |
针对当前字段相关度的评分权值,默认为1 |
coerce |
是否允许强制类似转化 true "1" => 1 false "1"<= 1 |
copy_to |
该字段运行将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询 |
doc_values |
为了提升排序和聚合效率,默认为true。如果确定不需要对该字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间(不支持text和annotated_text) |
dynamic ? |
控制是否可以动态添加新字段,默认为true(即新检测的字段将添加到映射中)。false时表示新检测的字段将被忽略,这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中,这些字段不会添加到映射中,必须显式添加新字段。strict:如果检测到新字段,则会引发异常并拒绝文档,必须将新字段显式添加到映射中。 |
eager_global_odrinals |
用于聚合的字段上,优化聚合性能。Frozen_indices(冻结索引):有些索引使用率高,会被并保存到内存中。有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据,Frozenindices的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或分钟基本不的,eager_global_ordinals不适用于Frozen indices |
enable |
是否创建倒排索引,可以对字段操作,也可以对索引操作。如果不创建索引,仍然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。PUT my_index{"mappings":{"enabled":false}} |
filedata |
查询时内存数据结果,在首次使用当前字段聚合、排序或者在脚本中使用时,需要字段为filedata数据结构,并创建倒排索引保存到堆中 |
fileds |
给filed创建多字段,用于不同目的(全文检索或者聚合分析索引排序) |
format |
格式化 |
ignore_above |
超长字段将被忽略 |
ignore_malformed |
忽略类型错误 |
index_options |
控制将哪些信息添加到反向索引中以进行搜索和突出显示,仅用于text字段 |
index_phrases |
提升exact_value查询速度,但是要消耗更多磁盘空间 |
index_prefixes |
前缀搜索。min_chars:前缀最小长度,> 0 ,默认为2(包含);max_charrs:前缀最大长度,< 20 ,默认为5(包含) |
meta |
附加元数据 |
normalizer |
|
norms |
是否禁用评分(在filter和聚合字段上应该禁用) |
null_value |
为null值设置默认值 |
position_increment_gap |
|
proterties |
处理mapping还可用于object的属性设置 |
search_analyzer |
设置单独的查询分析器 |
similarity |
为字段设置相关度算法,支持BM24、classic(TF-IDF)、Boolean |
store |
设置字段是否仅查询 |
term_vector |
运维参数 |
- 禁用元数据
- 好处
- 节省存储
- 坏处
- 不支持update、update_by_query和reindex API。
- 不支持高亮
- 不支持reindex、更改mapping分析器和版本升级
- 通过查看索引时使用的原始文档来调试查询或聚合的功能
- 将来有可能自动修复索引损坏
- 总结
- 如果只是为了节省磁盘,可以压缩索引比禁用_source更好
GET /product/_search
{
"_source": false,
"query": {
"match_all": {}
}
}
- 数据源过滤器
- 分类
- Including:结果中返回哪些field
- Excluding:结果中不要返回哪些field,不返回的field不代表不能通过该字段进行检索,因为元数据不存在不代表所有不存在。
- 使用
- 在mapping中定义过滤[[Elasticsearch教程入门到精通#^d20b46]]:支持通配符,但不推荐,因为mapping不可变。
- 常用过滤规则
"_source":"false," 禁用"_source":"obj.*","_source":["obj1.*","obj2.*"],"_sourc":{"includes":["obj1.*","obj2.*"],"excludes":["*.description"]}
- mapping定义过滤 ^d20b46
PUT /product2/
{
"mappings": {
"_source": {
"includes":[
"name",
"price"
],
"excludes":[
"desc",
"tags"
]
}
}
}
- 好处
- 节省存储
- 坏处
- 不支持update、update_by_query和reindex API。
- 不支持高亮
- 不支持reindex、更改mapping分析器和版本升级
- 通过查看索引时使用的原始文档来调试查询或聚合的功能
- 将来有可能自动修复索引损坏
- 总结
- 如果只是为了节省磁盘,可以压缩索引比禁用_source更好
GET /product/_search
{
"_source": false,
"query": {
"match_all": {}
}
}
- 分类
- Including:结果中返回哪些field
- Excluding:结果中不要返回哪些field,不返回的field不代表不能通过该字段进行检索,因为元数据不存在不代表所有不存在。
- 使用
- 在mapping中定义过滤[[Elasticsearch教程入门到精通#^d20b46]]:支持通配符,但不推荐,因为mapping不可变。
- 常用过滤规则
"_source":"false,"禁用"_source":"obj.*","_source":["obj1.*","obj2.*"],"_sourc":{"includes":["obj1.*","obj2.*"],"excludes":["*.description"]}
PUT /product2/
{
"mappings": {
"_source": {
"includes":[
"name",
"price"
],
"excludes":[
"desc",
"tags"
]
}
}
}
- 查询所有
GET /product/_search
- 带参数
GET /product/_search?q=name:xiaomi
- 分页
GET /prodect/_search?form=0&size=2&sort=price:asc
- 精准匹配
GET /product/_search?q=date:2021-06-01
- _all搜索
GET /product/_search?q=2021-06-01
GET /product/_search
GET /product/_search?q=name:xiaomi
GET /prodect/_search?form=0&size=2&sort=price:asc
GET /product/_search?q=date:2021-06-01
GET /product/_search?q=2021-06-01
对于keyword类型是精准查询,对于text是先分析在查询
GET /product/_search
{
"query": {
"match": {
"date": "2021-06-01"
}
}
}
对于keyword类型是精准查询,对于text是先分析在查询
GET /product/_search
{
"query": {
"match": {
"date": "2021-06-01"
}
}
}
GET /product/_search
{
"query": {
"match_all": {}
}
}
GET /product/_search
{
"query": {
"match_all": {}
}
}
select * from table wher a=xx and b=yyy
GET /product/_search
{
"query": {
"multi_match": {
"query": "phone huangmenji",
"fields": ["name","desc"]
}
}
}
select * from table wher a=xx and b=yyy
GET /product/_search
{
"query": {
"multi_match": {
"query": "phone huangmenji",
"fields": ["name","desc"]
}
}
}
GET /product/_search
{
"query": {
"match_phrase": {
"name": "xiaomi nfc"
}
}
}
GET /product/_search
{
"query": {
"match_phrase": {
"name": "xiaomi nfc"
}
}
}
匹配和搜索词项完全相等的结果【注意搜索text会被分词,搜索keyword才能匹配上】
- term和match_phrase区别
- match_phrase 会将检索关键词分词,match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,同时默认必须都是连续性的【3个条件】
- term不会将搜索词分词
- term和keryword的区别
- term是对于搜索词部分此
- keyword是字段类型,是对于source data中的字段值不分词
GET /product/_search
{
"query": {
"term": {
"name":"xiaomi phone"
}
}
}
#match_phrase
GET /product/_search
{
"query": {
"match_phrase": {
"name": "xiaomi phone"
}
}
}
匹配和搜索词项完全相等的结果【注意搜索text会被分词,搜索keyword才能匹配上】
- match_phrase 会将检索关键词分词,match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,同时默认必须都是连续性的【3个条件】
- term不会将搜索词分词
- term是对于搜索词部分此
- keyword是字段类型,是对于source data中的字段值不分词
GET /product/_search
{
"query": {
"term": {
"name":"xiaomi phone"
}
}
}
#match_phrase
GET /product/_search
{
"query": {
"match_phrase": {
"name": "xiaomi phone"
}
}
}
匹配和搜索词项列表中任意项匹配的结果,类似于MySql中的in语句【select * from table t where t.a in xxx 】
GET /product/_search
{
"query": {
"terms": {
"tags": [
"xingjiabi",
"buka"
]
}
}
}
匹配和搜索词项列表中任意项匹配的结果,类似于MySql中的in语句【select * from table t where t.a in xxx 】
GET /product/_search
{
"query": {
"terms": {
"tags": [
"xingjiabi",
"buka"
]
}
}
}
范围查找
GET /product/_search
{
"query": {
"range": {
"price": {
"gte": 399,
"lte": 1000
}
}
}
}
# 注意时区的用法
GET /product/_search
{
"query": {
"range": {
"date": {
"time_zone": "+08:00",
"gte": "now-10y/y",
"lte": "now/d"
}
}
}
}
范围查找
GET /product/_search
{
"query": {
"range": {
"price": {
"gte": 399,
"lte": 1000
}
}
}
}
# 注意时区的用法
GET /product/_search
{
"query": {
"range": {
"date": {
"time_zone": "+08:00",
"gte": "now-10y/y",
"lte": "now/d"
}
}
}
}
性能比query好一点
性能比query好一点
GET /product/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "phone"
}
},
"boost": 1.2
}
}
}
# 用作组合查询中
GET /product/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"name": "phone"
}
}
]
}
}
}
GET /product/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "phone"
}
},
"boost": 1.2
}
}
}
# 用作组合查询中
GET /product/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"name": "phone"
}
}
]
}
}
}
- 筛选数据
可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值(filter和must_not不会计算评分)。
可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值(filter和must_not不会计算评分)。
- must
- 必须满足子句(查询)必须出现在匹配的文档章,并将有助于得分。
- filter
- 过滤器,不计算相关度分数,chche子句查询必须出现在匹配的文档中。 但是不像must查询的分数将会被忽略。Filter子句在filter上下文中执行,这意味着计分被忽略,并且子句将被考虑用于缓存。
- should
- 可能满足or子句(查询)应该出现在匹配的文档中
- must_not
- 必须不满足不计算相关度分数 子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被沪铝,并且子句被视为用于缓存。因此将返回素有文档的分数。
minimum_should_match: 参数指定shuld返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或filter子句,则默认值为1,否则默认值为0.
- 必须满足子句(查询)必须出现在匹配的文档章,并将有助于得分。
- 过滤器,不计算相关度分数,chche子句查询必须出现在匹配的文档中。 但是不像must查询的分数将会被忽略。Filter子句在filter上下文中执行,这意味着计分被忽略,并且子句将被考虑用于缓存。
- 可能满足or子句(查询)应该出现在匹配的文档中
- 必须不满足不计算相关度分数 子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被沪铝,并且子句被视为用于缓存。因此将返回素有文档的分数。
minimum_should_match: 参数指定shuld返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句,而没有must或filter子句,则默认值为1,否则默认值为0.
GET product/_search
{
"_source": false,
"query": {
"bool": {
"must": [
{
"match": {
"name": "xiaomi phone"
}
},
{
"match": {
"desc": "shouji zhong"
}
}
]
}
}
}
GET product/_search
{
"_source": false,
"query": {
"bool": {
"must": [
{
"match": {
"name": "xiaomi phone"
}
},
{
"match": {
"desc": "shouji zhong"
}
}
]
}
}
}
GET product/_search
{
"_source": false,
"query": {
"bool": {
"filter": [
{
"match": {
"name": "xiaomi phone"
}
},
{
"match": {
"desc": "shouji zhong"
}
}
]
}
}
}
GET product/_search
{
"_source": false,
"query": {
"bool": {
"filter": [
{
"match": {
"name": "xiaomi phone"
}
},
{
"match": {
"desc": "shouji zhong"
}
}
]
}
}
}
GET product/_search
{
"_source": false,
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "xiaome phon"
}
},
{
"range": {
"price": {
"gte": 1000
}
}
}
]
}
}
}
GET product/_search
{
"_source": false,
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "xiaome phon"
}
},
{
"range": {
"price": {
"gte": 1000
}
}
}
]
}
}
}
GET product/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"name": "xiaome phon"
}
},
{
"range": {
"price": {
"gte": 4000
}
}
}
]
}
}
}
- 组合
# filter和must的关系为and
GET /product/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"price": {
"gte": 1000
}
}
}
],
"must": [
{
"match": {
"name": "xiaomi"
}
}
]
}
}
}
GET product/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"name": "xiaome phon"
}
},
{
"range": {
"price": {
"gte": 4000
}
}
}
]
}
}
}
# filter和must的关系为and
GET /product/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"price": {
"gte": 1000
}
}
}
],
"must": [
{
"match": {
"name": "xiaomi"
}
}
]
}
}
}
#later
- https://www.bilibili.com/video/BV1LY4y167n5?p=28&vd_source=c013484f4cbc43b024e86dcb9864399e
- 24min左右
# 注意should和filter/must的组合情况
# 没有minimum_should_match的话,默认为0条数据
GET /product/_search
{
"_source": false,
"query": {
"bool": {
"filter": [
{
"range": {
"price": {
"gte": 1000
}
}
}
],
"should": [
{
"match_phrase": {
"name": "nfc phone"
}
},
{
"match": {
"name": "erji"
}
}
],
"minimum_should_match": 1
}
}
}
# 注意should和filter/must的组合情况
# 没有minimum_should_match的话,默认为0条数据
# bool查询可以组合嵌套
GET /product/_search
{
"_source": false,
"query": {
"bool": {
"filter": [
{
"range": {
"price": {
"gte": 1000
}
}
}
],
"should": [
{
"match_phrase": {
"name": "nfc phone"
}
},
{
"match": {
"name": "erji"
}
},
{
"bool": {
"must": [
{
"range": {
"price": {
"gte": 900,
"lte": 5000
}
}
}
]
}
}
],
"minimum_should_match": 2
}
}
}
- https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis.html
文档规范化,提高召回率
- 停用词
- 时态转换
- 大小写
- 同义词
- 语气词
文档规范化,提高召回率
分词前的预处理,过滤无用字符
- HTML Strip Character Filter: httm_strip
- 参数:
- escaped_tags : 需要保留的html标签
DELETE cf_test_index
PUT cf_test_index
{
"settings": {
"analysis": {
"char_filter":{
"my_char_filter":{
"type":"html_strip",
"escaped_tags":["a"]
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":"my_char_filter"
}
}
}
}
}
GET /cf_test_index/_analyze
{
"analyzer": "my_analyzer",
"text": "<p>I'm so <a>happy</a>!</p>"
}
- Mapping Character Filter: type mapping
DELETE map_test_index
PUT map_test_index
{
"settings": {
"analysis": {
"char_filter":{
"my_char_filter":{
"type":"mapping",
"mappings":[
"滚 => *",
"垃 => *",
"圾 => *"
]
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":"my_char_filter"
}
}
}
}
}
GET /map_test_index/_analyze
{
"analyzer": "my_analyzer",
"text": "滚吧,垃圾!"
}
- Pattern Replace Characteer Filter: type pattern_replace
注意正则表达式不要写错了
DELETE pattern_filter_test_index
PUT pattern_filter_test_index
{
"settings": {
"analysis": {
"char_filter":{
"my_char_filter":{
"type":"pattern_replace",
"pattern":"(\\d{3})\\d{4}(\\d{4})",
//$1代表上面第一个()匹配项
"replacement":"$1****$2"
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
}
}
}
}
GET /pattern_filter_test_index/_analyze
{
"analyzer": "my_analyzer",
"text": "你得手机号是17611001200"
}
分词前的预处理,过滤无用字符
- 参数:
- escaped_tags : 需要保留的html标签
DELETE cf_test_index
PUT cf_test_index
{
"settings": {
"analysis": {
"char_filter":{
"my_char_filter":{
"type":"html_strip",
"escaped_tags":["a"]
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":"my_char_filter"
}
}
}
}
}
GET /cf_test_index/_analyze
{
"analyzer": "my_analyzer",
"text": "<p>I'm so <a>happy</a>!</p>"
}
DELETE map_test_index
PUT map_test_index
{
"settings": {
"analysis": {
"char_filter":{
"my_char_filter":{
"type":"mapping",
"mappings":[
"滚 => *",
"垃 => *",
"圾 => *"
]
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":"my_char_filter"
}
}
}
}
}
GET /map_test_index/_analyze
{
"analyzer": "my_analyzer",
"text": "滚吧,垃圾!"
}
注意正则表达式不要写错了
DELETE pattern_filter_test_index
PUT pattern_filter_test_index
{
"settings": {
"analysis": {
"char_filter":{
"my_char_filter":{
"type":"pattern_replace",
"pattern":"(\\d{3})\\d{4}(\\d{4})",
//$1代表上面第一个()匹配项
"replacement":"$1****$2"
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
}
}
}
}
GET /pattern_filter_test_index/_analyze
{
"analyzer": "my_analyzer",
"text": "你得手机号是17611001200"
}
停用词、时态转换、大小写转换、同义词转换、语气词处理等。比如:has=>have him=>he apples=>apple the/oh/a=> 干掉
- 同义词示例
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-synonym-graph-tokenfilter.html
DELETE my_synonym_index
# 注意文件
# https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-synonym-graph-tokenfilter.html
PUT my_synonym_index?pretty
{
"settings": {
"analysis": {
"filter": {
"my_synonym": {
"type": "synonym_graph",
"synonyms_path": "analysis/synonym.txt"
}
},
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": [
"my_synonym"
]
}
}
}
}
}
GET /my_synonym_index/_analyze
{
"text": ["daG"]
, "analyzer": "my_analyzer"
}
emperinter@lover:/app/elasticsearch/analysis$ more synonym.txt
蒙丢丢,mengdiou => 蒙迪欧
大G => 奔驰G级
霸道 => 普拉多
daG => prodo
停用词、时态转换、大小写转换、同义词转换、语气词处理等。比如:has=>have him=>he apples=>apple the/oh/a=> 干掉
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-synonym-graph-tokenfilter.html
DELETE my_synonym_index
# 注意文件
# https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-synonym-graph-tokenfilter.html
PUT my_synonym_index?pretty
{
"settings": {
"analysis": {
"filter": {
"my_synonym": {
"type": "synonym_graph",
"synonyms_path": "analysis/synonym.txt"
}
},
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": [
"my_synonym"
]
}
}
}
}
}
GET /my_synonym_index/_analyze
{
"text": ["daG"]
, "analyzer": "my_analyzer"
}
emperinter@lover:/app/elasticsearch/analysis$ more synonym.txt
蒙丢丢,mengdiou => 蒙迪欧
大G => 奔驰G级
霸道 => 普拉多
daG => prodo
GET /my_synonym_index/_analyze
{
"tokenizer": "ik_max_word",
"text":"我爱北京天安门"
}
- 场景分词器
- standard analyzer: 默认分词器,中文支持的不理想,会逐字拆分
- pattern tokenizer:以正则匹配分隔符,把文本拆分成若干词项。
- simple pattern tokenizer: 以正则匹配词项,速度比pattern tokenizer快。
- whitespace analyzer: 以空白符分隔
GET /my_synonym_index/_analyze
{
"tokenizer": "ik_max_word",
"text":"我爱北京天安门"
}
- standard analyzer: 默认分词器,中文支持的不理想,会逐字拆分
- pattern tokenizer:以正则匹配分隔符,把文本拆分成若干词项。
- simple pattern tokenizer: 以正则匹配词项,速度比pattern tokenizer快。
- whitespace analyzer: 以空白符分隔
- char_filter: 内置或自定义字符过滤器
- token_filter: 内置或自定义token filter
- tokenizer: 内置或自定义分词器
DELETE custom_analysis_test_index
# 注意my_tokenizer 有个空格
PUT custom_analysis_test_index
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"& => and",
"| => or"
]
},
"html_strip_char_filter":{
"type":"html_strip",
"eacaped_tags":["a"]
}
},
"filter": {
"my_stopword": {
"type": "stop",
"stop_words": [
"is",
"in",
"the",
"a",
"at",
"for"
]
}
},
"tokenizer": {
"my_tokenizer":{
"type":"pattern",
"pattern":"[ ,.!?]"
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"my_char_filter",
"html_strip_char_filter"
],
"tokenizer":"my_tokenizer"
}
}
}
}
}
GET /custom_analysis_test_index/_analyze
{
"analyzer": "my_analyzer",
"text":["What is ,<a>asdf . </a>ss in ? | & | is ! <p>in the a at for</p>"]
}
DELETE custom_analysis_test_index
# 注意my_tokenizer 有个空格
PUT custom_analysis_test_index
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"& => and",
"| => or"
]
},
"html_strip_char_filter":{
"type":"html_strip",
"eacaped_tags":["a"]
}
},
"filter": {
"my_stopword": {
"type": "stop",
"stop_words": [
"is",
"in",
"the",
"a",
"at",
"for"
]
}
},
"tokenizer": {
"my_tokenizer":{
"type":"pattern",
"pattern":"[ ,.!?]"
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"my_char_filter",
"html_strip_char_filter"
],
"tokenizer":"my_tokenizer"
}
}
}
}
}
GET /custom_analysis_test_index/_analyze
{
"analyzer": "my_analyzer",
"text":["What is ,<a>asdf . </a>ss in ? | & | is ! <p>in the a at for</p>"]
}
- https://github.com/medcl/elasticsearch-analysis-ik
-
远程安装
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
root@020ba19969e9:/usr/share/elasticsearch/bin# elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
-> Installing https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
[=================================================] 100%??
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See https://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-ik
-> Please restart Elasticsearch to activate any plugins installed
远程安装
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
root@020ba19969e9:/usr/share/elasticsearch/bin# elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
-> Installing https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
[=================================================] 100%??
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See https://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-ik
-> Please restart Elasticsearch to activate any plugins installed
- IKAnalyzer.cfg.xml: IK 分词配置文件
- 主词库: main.dic
- 英文停用词:stopword.dic,不会建立在倒排索引重
- 特殊词库
- quantificer.dic: 特殊词库:计量单位等
- suffix.dic: 特殊词库: 后缀名
- surname.dic: 特殊词库:百家姓
- preposition:特殊词库:语气词
- 自定义词库
- 网络词汇、流行词、自造词等。
- quantificer.dic: 特殊词库:计量单位等
- suffix.dic: 特殊词库: 后缀名
- surname.dic: 特殊词库:百家姓
- preposition:特殊词库:语气词
- 网络词汇、流行词、自造词等。
#ik_max_word使用较多
GET /custom_analysis_test_index/_analyze
{
"analyzer": "ik_max_word",
"text":"我爱中华人民共和国"
}
GET /custom_analysis_test_index/_analyze
{
"analyzer": "ik_smart",
"text":"我爱中华人民共和国"
}
#ik_max_word使用较多
GET /custom_analysis_test_index/_analyze
{
"analyzer": "ik_max_word",
"text":"我爱中华人民共和国"
}
GET /custom_analysis_test_index/_analyze
{
"analyzer": "ik_smart",
"text":"我爱中华人民共和国"
}
防止重启影响生成
防止重启影响生成
https://github.com/medcl/elasticsearch-analysis-ik
- 更改ik配置文件
emperinter@lover:/app/elasticsearch/analysis-ik$ more IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 优点
- 上手简单
- 缺点
- 词库管理不方便,要直接操作磁盘文件,检索页maf
- 文件读写没有专业的性能优化不好
- 多一层服务接口调用和网络传输
https://github.com/medcl/elasticsearch-analysis-ik
emperinter@lover:/app/elasticsearch/analysis-ik$ more IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 上手简单
- 词库管理不方便,要直接操作磁盘文件,检索页maf
- 文件读写没有专业的性能优化不好
- 多一层服务接口调用和网络传输
需要更改ES 源码,官方貌似并没有推荐过这种方式。
需要更改ES 源码,官方貌似并没有推荐过这种方式。
GET /index_name/_search
{
"aggs": {
"<aggs_name>": {
"AGG_TYPE": {
"filed":"<filed_name>"
}
},
"<aggs_name2>": {
"AGG_TYPE": {
"filed":"<filed_name>"
}
}
}
}
GET /index_name/_search
{
"aggs": {
"<aggs_name>": {
"AGG_TYPE": {
"filed":"<filed_name>"
}
},
"<aggs_name2>": {
"AGG_TYPE": {
"filed":"<filed_name>"
}
}
}
}
分类,类似于Group By
GET /product/_search
{
"size": 0,
"aggs": {
"aggs_tag": {
"terms": {
"field": "tags.keyword",
"size": 30,
"order": {
"_count": "asc"
}
}
}
}
}
分类,类似于Group By
GET /product/_search
{
"size": 0,
"aggs": {
"aggs_tag": {
"terms": {
"field": "tags.keyword",
"size": 30,
"order": {
"_count": "asc"
}
}
}
}
}
AVG平均值、Max最大值、Min最小值、Sum求和、Value Count 计数、Stats统计聚合、Top Hits聚合、cardinality基数(去重)
# 统计最贵,最便宜和平均价格三个指标
GET /product/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price":{
"min": {
"field": "price"
}
},
"avg_price":{
"avg": {
"field": "price"
}
}
}
}
GET /product/_search
{
"size": 0,
"aggs": {
"price_status": {
"stats": {
"field": "price"
}
}
}
}
# 按照name去重的数量
GET /product/_search
{
"size": 0,
"aggs": {
"name_count": {
"cardinality": {
"field": "name.keyword"
}
}
}
}
AVG平均值、Max最大值、Min最小值、Sum求和、Value Count 计数、Stats统计聚合、Top Hits聚合、cardinality基数(去重)
# 统计最贵,最便宜和平均价格三个指标
GET /product/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price":{
"min": {
"field": "price"
}
},
"avg_price":{
"avg": {
"field": "price"
}
}
}
}
GET /product/_search
{
"size": 0,
"aggs": {
"price_status": {
"stats": {
"field": "price"
}
}
}
}
# 按照name去重的数量
GET /product/_search
{
"size": 0,
"aggs": {
"name_count": {
"cardinality": {
"field": "name.keyword"
}
}
}
}
对聚合的结果二次聚合
- 分类
- 父级
- 兄弟级
- 语法
- buckets_path
- 注意buckets_path的第一个参数应该是和它平级的名称
# 管道聚合
# 统计平均价格最低的商品分类
# 先分类再计算平均价格,最后再计算最小值
GET /product/_search
{
"size": 0,
"aggs": {
"product_type": {
"terms": {
"field": "type.keyword",
"size": 10
},
"aggs": {
"product_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"min_bucket":{
"min_bucket": {
"buckets_path": "product_type>product_avg_price"
}
}
}
}
对聚合的结果二次聚合
- 父级
- 兄弟级
- buckets_path
- 注意buckets_path的第一个参数应该是和它平级的名称
# 管道聚合
# 统计平均价格最低的商品分类
# 先分类再计算平均价格,最后再计算最小值
GET /product/_search
{
"size": 0,
"aggs": {
"product_type": {
"terms": {
"field": "type.keyword",
"size": 10
},
"aggs": {
"product_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"min_bucket":{
"min_bucket": {
"buckets_path": "product_type>product_avg_price"
}
}
}
}
- 语法
注意嵌套级别
GET /index_name/_search
{
"size": 0,
"aggs": {
"<agg_name>": {
"<AGG_TYPE>": {
"field":"<field_name>"
},
"aggs": {
"<agg_name_child>": {
"<AGG_TYPE>": {
"field":"<field_name>"
}
}
}
}
}
}
- 示例
# 嵌套聚合
# 统计不同类型商品的不同级别的数量
GET /product/_search
{
"size": 0,
"aggs": {
"type": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"lv_agg": {
"terms": {
"field": "lv.keyword"
}
}
}
}
}
}
# 按照lv分桶,输出每个桶的具体价格信息
GET /product/_search
{
"size": 0,
"aggs": {
"lv_price": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"price": {
"stats": {
"field": "price"
}
}
}
}
}
}
# 统计不同类型商品,不同档次的价格信息
GET /product/_search
{
"size": 0,
"aggs": {
"product_type": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"product_lv": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"product_price_status": {
"stats": {
"field": "price"
}
}
}
}
}
}
}
}
# 统计不同类型商品,不同档次的价格信息 标签信息
# 注意aggs是可以多个参数的
GET /product/_search
{
"size": 0,
"aggs": {
"product_type": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"product_lv": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"product_price_status": {
"stats": {
"field": "price"
}
},
"diff_tags":{
"terms": {
"field": "tags.keyword"
}
}
}
}
}
}
}
}
# 统计每个商品类型中 不同档次分类商品中 平均价格最大的档次
# 注意buckets_path的第一个参数应该是和它平级的名称
GET /product/_search
{
"size": 0,
"aggs": {
"diff_type": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"diff_lv": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"max_avg_price_lv":{
"max_bucket": {
"buckets_path": "diff_lv>avg_price"
}
}
}
}
}
}
注意嵌套级别
GET /index_name/_search
{
"size": 0,
"aggs": {
"<agg_name>": {
"<AGG_TYPE>": {
"field":"<field_name>"
},
"aggs": {
"<agg_name_child>": {
"<AGG_TYPE>": {
"field":"<field_name>"
}
}
}
}
}
}
# 嵌套聚合
# 统计不同类型商品的不同级别的数量
GET /product/_search
{
"size": 0,
"aggs": {
"type": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"lv_agg": {
"terms": {
"field": "lv.keyword"
}
}
}
}
}
}
# 按照lv分桶,输出每个桶的具体价格信息
GET /product/_search
{
"size": 0,
"aggs": {
"lv_price": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"price": {
"stats": {
"field": "price"
}
}
}
}
}
}
# 统计不同类型商品,不同档次的价格信息
GET /product/_search
{
"size": 0,
"aggs": {
"product_type": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"product_lv": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"product_price_status": {
"stats": {
"field": "price"
}
}
}
}
}
}
}
}
# 统计不同类型商品,不同档次的价格信息 标签信息
# 注意aggs是可以多个参数的
GET /product/_search
{
"size": 0,
"aggs": {
"product_type": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"product_lv": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"product_price_status": {
"stats": {
"field": "price"
}
},
"diff_tags":{
"terms": {
"field": "tags.keyword"
}
}
}
}
}
}
}
}
# 统计每个商品类型中 不同档次分类商品中 平均价格最大的档次
# 注意buckets_path的第一个参数应该是和它平级的名称
GET /product/_search
{
"size": 0,
"aggs": {
"diff_type": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"diff_lv": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"max_avg_price_lv":{
"max_bucket": {
"buckets_path": "diff_lv>avg_price"
}
}
}
}
}
}
GET /product/_search
{
"size": 10,
"query": {
"range": {
"price": {
"gte": 5000
}
}
},
"aggs": {
"tag_bucket": {
"terms": {
"field": "tags.keyword"
}
}
}
}
GET /product/_search
{
"query": {
"bool": {
"filter": {
"range": {
"price": {
"gte": 5000
}
}
},
"boost": 1.2
}
},
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
}
}
GET /product/_search
{
"size": 10,
"query": {
"range": {
"price": {
"gte": 5000
}
}
},
"aggs": {
"tag_bucket": {
"terms": {
"field": "tags.keyword"
}
}
}
}
GET /product/_search
{
"query": {
"bool": {
"filter": {
"range": {
"price": {
"gte": 5000
}
}
},
"boost": 1.2
}
},
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
}
}
GET /product/_search
{
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
},
"post_filter": {
"term": {
"tags.keyword": "性价比"
}
}
}
GET /product/_search
{
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
},
"post_filter": {
"term": {
"tags.keyword": "性价比"
}
}
}
## 取消查询条件&&查询条件嵌套
GET /product/_search
{
"size": 10,
"query": {
"range": {
"price": {
"gte": 4000
}
}
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price":{
"min": {
"field": "price"
}
},
"avg_price":{
"avg": {
"field": "price"
}
},
"all_avg_price":{
"global": {},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
- 复杂的用法
# multi_avg_price的filter何query的查询是产生了交集
GET /product/_search
{
"size": 10,
"query": {
"range": {
"price": {
"gte": 4000
}
}
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price":{
"min": {
"field": "price"
}
},
"avg_price":{
"avg": {
"field": "price"
}
},
"all_avg_price":{
"global": {},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"multi_avg_price":{
"filter": {
"range":{
"price":{
"lte":4500
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
## 取消查询条件&&查询条件嵌套
GET /product/_search
{
"size": 10,
"query": {
"range": {
"price": {
"gte": 4000
}
}
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price":{
"min": {
"field": "price"
}
},
"avg_price":{
"avg": {
"field": "price"
}
},
"all_avg_price":{
"global": {},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
# multi_avg_price的filter何query的查询是产生了交集
GET /product/_search
{
"size": 10,
"query": {
"range": {
"price": {
"gte": 4000
}
}
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price":{
"min": {
"field": "price"
}
},
"avg_price":{
"avg": {
"field": "price"
}
},
"all_avg_price":{
"global": {},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
},
"multi_avg_price":{
"filter": {
"range":{
"price":{
"lte":4500
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
- 排序方式
- _doc
- _key
- _count
- 简单排序
GET /product/_search
{
"size": 0,
"aggs": {
"fisrt_sort": {
"terms": {
"field": "tags.keyword",
"size": 30,
"order": {
"_count": "desc"
}
},
"aggs": {
"second": {
"terms": {
"field": "lv.keyword",
"order": {
"_count": "asc"
}
}
}
}
}
}
}
- 多层聚合排序
# 多层聚合
# 注意第一层order的用法
GET /product/_search
{
"size": 0,
"aggs": {
"type_avg_price": {
"terms": {
"field": "type.keyword",
"order": {
"aggs_stats>stats.min": "desc"
}
},
"aggs": {
"aggs_stats": {
"filter": {
"terms": {
"type.keyword": [
"耳机",
"手机",
"电视"
]
}
},
"aggs": {
"stats": {
"stats": {
"field": "price"
}
}
}
}
}
}
}
}
- _doc
- _key
- _count
GET /product/_search
{
"size": 0,
"aggs": {
"fisrt_sort": {
"terms": {
"field": "tags.keyword",
"size": 30,
"order": {
"_count": "desc"
}
},
"aggs": {
"second": {
"terms": {
"field": "lv.keyword",
"order": {
"_count": "asc"
}
}
}
}
}
}
}
# 多层聚合
# 注意第一层order的用法
GET /product/_search
{
"size": 0,
"aggs": {
"type_avg_price": {
"terms": {
"field": "type.keyword",
"order": {
"aggs_stats>stats.min": "desc"
}
},
"aggs": {
"aggs_stats": {
"filter": {
"terms": {
"type.keyword": [
"耳机",
"手机",
"电视"
]
}
},
"aggs": {
"stats": {
"stats": {
"field": "price"
}
}
}
}
}
}
}
}
^445511
# missing: 空值的处理罗偶极,对字段的控制赋予默认值
GET /product/_search
{
"size": 0,
"aggs": {
"price_histogram": {
"histogram": {
"field": "price",
"interval": 1000,
"keyed": true,
"min_doc_count": 1,
"missing": 1999
}
}
}
}
# missing: 空值的处理罗偶极,对字段的控制赋予默认值
GET /product/_search
{
"size": 0,
"aggs": {
"price_histogram": {
"histogram": {
"field": "price",
"interval": 1000,
"keyed": true,
"min_doc_count": 1,
"missing": 1999
}
}
}
}
注意extended_bounds的用法
GET /product/_search
{
"size": 0,
"aggs": {
"my_date_histogram": {
"date_histogram": {
"field": "creattime",
"calendar_interval": "month",
"format": "yyyy-MM",
"extended_bounds": {
"min": "2020-01",
"max": "2020-12"
},
"order": {
"_count": "desc"
}
}
}
}
}
- auto_date_histogram
GET /product/_search
{
"size": 0,
"aggs": {
"my_auto_histogram": {
"auto_date_histogram": {
"field": "creattime",
"format": "yyyy-MM-dd",
"buckets":180
}
}
}
}
注意extended_bounds的用法
GET /product/_search
{
"size": 0,
"aggs": {
"my_date_histogram": {
"date_histogram": {
"field": "creattime",
"calendar_interval": "month",
"format": "yyyy-MM",
"extended_bounds": {
"min": "2020-01",
"max": "2020-12"
},
"order": {
"_count": "desc"
}
}
}
}
}
GET /product/_search
{
"size": 0,
"aggs": {
"my_auto_histogram": {
"auto_date_histogram": {
"field": "creattime",
"format": "yyyy-MM-dd",
"buckets":180
}
}
}
}
^73e926
- 累加和的情况
# my_cumulative_sum累加和/总计
GET /product/_search
{
"size": 0,
"aggs": {
"my_date_histogram": {
"date_histogram": {
"field": "creattime",
"calendar_interval": "month",
"format": "yyyy-MM",
"extended_bounds": {
"min": "2020-01",
"max": "2020-12"
},
"order": {
"_count": "desc"
}
},
"aggs": {
"sum_agg": {
"sum": {
"field": "price"
}
},
"my_cumulative_sum":{
"cumulative_sum": {
"buckets_path": "sum_agg"
}
}
}
}
}
}
- percentiles 由百分比区间求数据
## 百分位统计
GET /product/_search
{
"size": 0,
"aggs": {
"price_precentiles": {
"percentiles": {
"field": "price",
"percents": [
1,
5,
25,
50,
75,
95,
99
]
}
}
}
}
- percentile_ranks 由数据求百分比区间
TDigest算法
GET /product/_search
{
"size": 0,
"aggs": {
"price_precentiles": {
"percentile_ranks": {
"field": "price",
"values": [
1000,
2000,
3000,
4000,
5000,
6000
]
}
}
}
}
## 百分位统计
GET /product/_search
{
"size": 0,
"aggs": {
"price_precentiles": {
"percentiles": {
"field": "price",
"percents": [
1,
5,
25,
50,
75,
95,
99
]
}
}
}
}
TDigest算法
GET /product/_search
{
"size": 0,
"aggs": {
"price_precentiles": {
"percentile_ranks": {
"field": "price",
"values": [
1000,
2000,
3000,
4000,
5000,
6000
]
}
}
}
}
ES 支持的专门用于复杂场景下支持自定义编程的强大的脚本功能。
- ES支持的Scripts
- Groovy: ES1.4.x - 5.0 的默认脚本语言
- painless: 专门用于ES的语言,用于内联和存储脚本,类似于Java,也有注释、关键字、类型、变量、函数等,是一种安全的脚本语言。
-
其它
- expression: 每个文档的开销较低,表达式的作用更多,可以非常快速地执行,甚至比编写native脚本还是要更快,支持JavaScript语法的子集:单个表达式。缺点是只能访问数字、布尔值、日期和geo_point字段,存储的字段不可用。
- mustache: 提供模板参数化查询
- 特点
- 优点
- 语法简单,学习成本低
- 灵活度高,可编程能力强
- 性能相较于其它脚本语言更高
- 安全性好
- 缺点
- 独立语言,虽然易学但仍需要单独学习
- 相较于DSL性能低
- 不适用于非复杂的业务场景。
- 语法
## ES 脚本
## 语法: ctx._source.<field-name>
GET /product/_search/
{
"query": {
"term": {
"_id": {
"value": "3"
}
}
}
}
POST /product/_update/3
{
"script": {
"source": "ctx._source.price-=1"
}
}
POST /product/_update/3
{
"script": {
"source": "ctx._source.price-=ctx._version"
}
}
# 简写
POST /product/_update/3
{
"script": "ctx._source.price-=1"
}
ES 支持的专门用于复杂场景下支持自定义编程的强大的脚本功能。
- Groovy: ES1.4.x - 5.0 的默认脚本语言
- painless: 专门用于ES的语言,用于内联和存储脚本,类似于Java,也有注释、关键字、类型、变量、函数等,是一种安全的脚本语言。
-
其它
- expression: 每个文档的开销较低,表达式的作用更多,可以非常快速地执行,甚至比编写native脚本还是要更快,支持JavaScript语法的子集:单个表达式。缺点是只能访问数字、布尔值、日期和geo_point字段,存储的字段不可用。
- mustache: 提供模板参数化查询
- 优点
- 语法简单,学习成本低
- 灵活度高,可编程能力强
- 性能相较于其它脚本语言更高
- 安全性好
- 缺点
- 独立语言,虽然易学但仍需要单独学习
- 相较于DSL性能低
- 不适用于非复杂的业务场景。
## ES 脚本
## 语法: ctx._source.<field-name>
GET /product/_search/
{
"query": {
"term": {
"_id": {
"value": "3"
}
}
}
}
POST /product/_update/3
{
"script": {
"source": "ctx._source.price-=1"
}
}
POST /product/_update/3
{
"script": {
"source": "ctx._source.price-=ctx._version"
}
}
# 简写
POST /product/_update/3
{
"script": "ctx._source.price-=1"
}
- 索引备份
POST _reindex
{
"source": {
"index": "product"
},
"dest": {
"index": "product2"
}
}
- 新增/修改
# 新增/修改
POST /product2/_update/2
{
"script": {
"lang": "painless",
"source": "ctx._source.tags.add('无线充电')"
}
}
- upsert= update+insert
# upsert
# 有则update无则insert
POST product2/_update/15
{
"script": {
"lang": "painless",
"source": "ctx._source.price+=100"
},
"upsert": {
"name":"小米手机10",
"desc":"充电快!",
"price":2000
}
}
- 删除
# delete
POST /product2/_update/11
{
"script": {
"lang": "painless",
"source": "ctx.op='delete'"
}
}
- 查询 painless expression
# painlesss查询
POST /product2/_search
{
"script_fields": {
"my_price": {
"script": {
"lang": "expression",
"source": "doc['price'] * 0.9"
}
}
}
}
# expression 查询
POST /product2/_search
{
"script_fields": {
"my_price": {
"script": {
"lang": "painless",
"source": "doc['price'].value * 0.9"
}
}
}
}
POST _reindex
{
"source": {
"index": "product"
},
"dest": {
"index": "product2"
}
}
# 新增/修改
POST /product2/_update/2
{
"script": {
"lang": "painless",
"source": "ctx._source.tags.add('无线充电')"
}
}
# upsert
# 有则update无则insert
POST product2/_update/15
{
"script": {
"lang": "painless",
"source": "ctx._source.price+=100"
},
"upsert": {
"name":"小米手机10",
"desc":"充电快!",
"price":2000
}
}
# delete
POST /product2/_update/11
{
"script": {
"lang": "painless",
"source": "ctx.op='delete'"
}
}
# painlesss查询
POST /product2/_search
{
"script_fields": {
"my_price": {
"script": {
"lang": "expression",
"source": "doc['price'] * 0.9"
}
}
}
}
# expression 查询
POST /product2/_search
{
"script_fields": {
"my_price": {
"script": {
"lang": "painless",
"source": "doc['price'].value * 0.9"
}
}
}
}
- 减少重复编译脚本过程
-
默认缓存是100MB
-
单参数
# 默认缓存是100M
POST product2/_update/6
{
"script": {
"lang": "painless",
"source": "ctx._source.tags.add(params.tag_name)",
"params": {
"tag_name":"无线秒充"
}
}
}
- 多个参数
GET /product2/_search
{
"script_fields": {
"original_price":{
"script":{
"lang": "painless",
"source": "doc['price'].value"
}
}
,
"discount_price": {
"script": {
"lang": "painless",
"source": "[doc['price'].value * params.discount_8,doc['price'].value * params.discount_7,doc['price'].value * params.discount_6,doc['price'].value * params.discount_5]",
"params": {
"discount_8":0.8,
"discount_7":0.7,
"discount_6":0.6,
"discount_5":0.5
}
}
}
}
}
默认缓存是100MB
单参数
# 默认缓存是100M
POST product2/_update/6
{
"script": {
"lang": "painless",
"source": "ctx._source.tags.add(params.tag_name)",
"params": {
"tag_name":"无线秒充"
}
}
}
GET /product2/_search
{
"script_fields": {
"original_price":{
"script":{
"lang": "painless",
"source": "doc['price'].value"
}
}
,
"discount_price": {
"script": {
"lang": "painless",
"source": "[doc['price'].value * params.discount_8,doc['price'].value * params.discount_7,doc['price'].value * params.discount_6,doc['price'].value * params.discount_5]",
"params": {
"discount_8":0.8,
"discount_7":0.7,
"discount_6":0.6,
"discount_5":0.5
}
}
}
}
}
_scriprts/{模板id}
- 创建
# 创建
# 写入缓存中
POST _scripts/calculate_discount
{
"script": {
"lang": "painless",
"source": "doc.price.value * params.discount"
}
}
- 查看
# 查看
GET _scripts/calculate_discount
- 使用
# 使用
GET product2/_search
{
"script_fields": {
"original_price": {
"script": {
"lang": "painless",
"source": "doc['price'].value"
}
},
"discount_fields": {
"script": {
"id": "calculate_discount",
"params": {
"discount": 0.8
}
}
}
}
}
_scriprts/{模板id}
# 创建
# 写入缓存中
POST _scripts/calculate_discount
{
"script": {
"lang": "painless",
"source": "doc.price.value * params.discount"
}
}
# 查看
GET _scripts/calculate_discount
# 使用
GET product2/_search
{
"script_fields": {
"original_price": {
"script": {
"lang": "painless",
"source": "doc['price'].value"
}
},
"discount_fields": {
"script": {
"id": "calculate_discount",
"params": {
"discount": 0.8
}
}
}
}
}
- simple case
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
ctx._source.tags.add(params.tag_name);
ctx._source.price-=100;
""",
"params": {
"tag_name":"无线秒充"
}
}
}
- 复杂
# 正则
# like %小米%
# 有则更改
# 没有result返回noop
POST product2/_update/3
{
"script": {
"lang": "painless",
"source": """
if(ctx._source.name ==~ /[\s\S]*小米[\s\S]*/){
ctx._source.name+="***|"
}else{
ctx.op = "noop"
}
""",
"params": {
"tag_name":"无线秒充"
}
}
}
## 日期
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
if(ctx._source.creattime ==~ /\d{4}-\d{2}-\d{2}[\s\S]*/){
ctx._source.name+="***|"
}else{
ctx.op = "noop"
}
"""
}
}
# 统计所有价格大于5000的tag数量,不考虑重复情况
# 注意其中的循环统计用法
GET /product2/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 5000
}
}
},
"boost": 1.2
}
},
"aggs": {
"taga_agg": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for(int i = 0;i < doc['tags.keyword'].length;i++){
total++
}
return total
"""
}
}
}
}
}
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
ctx._source.tags.add(params.tag_name);
ctx._source.price-=100;
""",
"params": {
"tag_name":"无线秒充"
}
}
}
# 正则
# like %小米%
# 有则更改
# 没有result返回noop
POST product2/_update/3
{
"script": {
"lang": "painless",
"source": """
if(ctx._source.name ==~ /[\s\S]*小米[\s\S]*/){
ctx._source.name+="***|"
}else{
ctx.op = "noop"
}
""",
"params": {
"tag_name":"无线秒充"
}
}
}
## 日期
POST product2/_update/1
{
"script": {
"lang": "painless",
"source": """
if(ctx._source.creattime ==~ /\d{4}-\d{2}-\d{2}[\s\S]*/){
ctx._source.name+="***|"
}else{
ctx.op = "noop"
}
"""
}
}
# 统计所有价格大于5000的tag数量,不考虑重复情况
# 注意其中的循环统计用法
GET /product2/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 5000
}
}
},
"boost": 1.2
}
},
"aggs": {
"taga_agg": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for(int i = 0;i < doc['tags.keyword'].length;i++){
total++
}
return total
"""
}
}
}
}
}
- 一些早期版本是默认禁用正则的,需要手动开启
script.painless.regex.enables : true
- 数据
PUT test_index/_bulk?refresh
{"index":{"_id":1}}
{"ajbh":"12345","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三","NL":"30","SF":"男"},{"XM":"李四","NL":"31","SF":"男"},{"XM":"王五","NL":"30","SF":"女"},{"XM":"赵六","NL":"23","SF":"男"}]}
{"index":{"_id":2}}
{"ajbh":"563245","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三2","NL":"30","SF":"男"},{"XM":"李四2","NL":"31","SF":"男"},{"XM":"王五2","NL":"30","SF":"女"},{"XM":"赵六2","NL":"23","SF":"男"}]}
{"index":{"_id":3}}
{"ajbh":"12345","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三3","NL":"30","SF":"男"},{"XM":"李四3","NL":"31","SF":"男"},{"XM":"王五3","NL":"30","SF":"女"},{"XM":"赵六3","NL":"23","SF":"男"}]}
- 复杂类似错误用法
# object nested
# 遇到复杂类型是不能用doc
# doc['field'].value 只能用于简单类型
# params['_source']['field']
GET /test_index/_search
{
"aggs": {
"sum_person": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for (int i = 0;i < doc['jsbax_sjjh2_xz_ryjbxx_cleaning'].length;i++){
if(doc['jsbax_sjjh2_xz_ryjbxx_cleaning'][i]['SF'] == '男'){
total ++
}
}
return total;
"""
}
}
}
}
}
- 复杂类型正确用法
GET /test_index/_search
{
"aggs": {
"sum_person": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for (int i = 0;i < params['_source']['jsbax_sjjh2_xz_ryjbxx_cleaning'].length;i++){
if(params['_source']['jsbax_sjjh2_xz_ryjbxx_cleaning'][i]['SF'] == '男'){
total ++
}
}
return total;
"""
}
}
}
}
}
script.painless.regex.enables : true
PUT test_index/_bulk?refresh
{"index":{"_id":1}}
{"ajbh":"12345","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三","NL":"30","SF":"男"},{"XM":"李四","NL":"31","SF":"男"},{"XM":"王五","NL":"30","SF":"女"},{"XM":"赵六","NL":"23","SF":"男"}]}
{"index":{"_id":2}}
{"ajbh":"563245","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三2","NL":"30","SF":"男"},{"XM":"李四2","NL":"31","SF":"男"},{"XM":"王五2","NL":"30","SF":"女"},{"XM":"赵六2","NL":"23","SF":"男"}]}
{"index":{"_id":3}}
{"ajbh":"12345","ajme":"立案案件","lasj":"2020/05/21 13:25:23","jsbax_sjjh2_xz_ryjbxx_cleaning":[{"XM":"张三3","NL":"30","SF":"男"},{"XM":"李四3","NL":"31","SF":"男"},{"XM":"王五3","NL":"30","SF":"女"},{"XM":"赵六3","NL":"23","SF":"男"}]}
# object nested
# 遇到复杂类型是不能用doc
# doc['field'].value 只能用于简单类型
# params['_source']['field']
GET /test_index/_search
{
"aggs": {
"sum_person": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for (int i = 0;i < doc['jsbax_sjjh2_xz_ryjbxx_cleaning'].length;i++){
if(doc['jsbax_sjjh2_xz_ryjbxx_cleaning'][i]['SF'] == '男'){
total ++
}
}
return total;
"""
}
}
}
}
}
GET /test_index/_search
{
"aggs": {
"sum_person": {
"sum": {
"script": {
"lang": "painless",
"source": """
int total = 0;
for (int i = 0;i < params['_source']['jsbax_sjjh2_xz_ryjbxx_cleaning'].length;i++){
if(params['_source']['jsbax_sjjh2_xz_ryjbxx_cleaning'][i]['SF'] == '男'){
total ++
}
}
return total;
"""
}
}
}
}
}
- 复杂
GET /_mget
{
"docs":[
{
"_index":"product",
"_id":2
},
{
"_index":"product",
"_id":3
}
]
}
- easy
GET product/_mget
{
"ids":[
2,
3,
4]
}
- 指定字段
GET /_mget
{
"docs": [
{
"_index": "product",
"_id": 2,
"_source": [
"name",
"price"
]
},
{
"_index": "product",
"_id": 3,
"_source":{
"exclude":[
"lv",
"type"
]
}
}
]
}
GET /_mget
{
"docs":[
{
"_index":"product",
"_id":2
},
{
"_index":"product",
"_id":3
}
]
}
GET product/_mget
{
"ids":[
2,
3,
4]
}
GET /_mget
{
"docs": [
{
"_index": "product",
"_id": 2,
"_source": [
"name",
"price"
]
},
{
"_index": "product",
"_id": 3,
"_source":{
"exclude":[
"lv",
"type"
]
}
}
]
}
PUT /test_index/_doc/1/_create
{
"test_field":"test",
"test_title":"title"
}
PUT /test_index/_create/3
{
"test_field":"test",
"test_title":"title"
}
- 自动生成id
POST /test_index/_doc
{
"test_field":"test",
"test_title":"title"
}
PUT /test_index/_doc/1/_create
{
"test_field":"test",
"test_title":"title"
}
PUT /test_index/_create/3
{
"test_field":"test",
"test_title":"title"
}
POST /test_index/_doc
{
"test_field":"test",
"test_title":"title"
}
只是标记成删除了
DELETE /test_index/_doc/3
只是标记成删除了
DELETE /test_index/_doc/3
PUT /test_index/_doc/oru0oIIBwVhBj7hhLYLT
{
"test_field": "test 1",
"test_title": "title 1"
}
POST /test_index/_update/oru0oIIBwVhBj7hhLYLT/
{
"doc": {
"test_field": "test 3",
"test_title": "title 3"
}
}
PUT /test_index/_doc/oru0oIIBwVhBj7hhLYLT
{
"test_field": "test 1",
"test_title": "title 1"
}
POST /test_index/_update/oru0oIIBwVhBj7hhLYLT/
{
"doc": {
"test_field": "test 3",
"test_title": "title 3"
}
}
可以是创建(不存在),也可以是全量替换(已存在)
PUT /test_index/_doc/oru0oIIBwVhBj7hhLYLT?op_type=index
{
"test_field": "test 2",
"test_title": "title 2"
}
PUT /test_index/_doc/5?op_type=index
{
"test_field": "test 2",
"test_title": "title ",
"test_name": "test"
}
- ?filter_path=items.*.error
> 只输出错误信息,适用于批量操作数据量较大的情况下使用。
PUT /test_index/_create/3?filter_path=items.*.error
{
"test_field":"test",
"test_title":"title"
}
可以是创建(不存在),也可以是全量替换(已存在)
PUT /test_index/_doc/oru0oIIBwVhBj7hhLYLT?op_type=index
{
"test_field": "test 2",
"test_title": "title 2"
}
PUT /test_index/_doc/5?op_type=index
{
"test_field": "test 2",
"test_title": "title ",
"test_name": "test"
}
> 只输出错误信息,适用于批量操作数据量较大的情况下使用。
PUT /test_index/_create/3?filter_path=items.*.error
{
"test_field":"test",
"test_title":"title"
}
工具
- 格式
删除没有元数据,当数据量大时,注意使用?filter_path=items.*.error
#POST /_bulk
POST /<index_name>/_bulk
{"action":{"metadata"}}
{"data"}
POST _bulk
{"delete":{"_index":"product","_id":2}}
{"create":{"_index":"product","_id":2}}
{"name":"_bulk create"}
{"update":{"_index":"product","_id":4}}
{"doc":{"name":"_bulk update 2"}}
{"delete":{"_index":"product","_id":1000}}
{"create":{"_index":"product","_id":2}}
{"name":"_bulk create"}
# 只把错误信息显示出来
POST _bulk?filter_path=items.*.error
{"delete":{"_index":"product","_id":2}}
{"create":{"_index":"product","_id":2}}
{"name":"_bulk create"}
{"update":{"_index":"product","_id":4}}
{"doc":{"name":"_bulk update 2"}}
{"delete":{"_index":"product","_id":1000}}
{"create":{"_index":"product","_id":2}}
{"name":"_bulk create"}
- 好处
- 不消耗额外内存
- 坏处
- 可读性查
工具
删除没有元数据,当数据量大时,注意使用?filter_path=items.*.error
#POST /_bulk
POST /<index_name>/_bulk
{"action":{"metadata"}}
{"data"}
POST _bulk
{"delete":{"_index":"product","_id":2}}
{"create":{"_index":"product","_id":2}}
{"name":"_bulk create"}
{"update":{"_index":"product","_id":4}}
{"doc":{"name":"_bulk update 2"}}
{"delete":{"_index":"product","_id":1000}}
{"create":{"_index":"product","_id":2}}
{"name":"_bulk create"}
# 只把错误信息显示出来
POST _bulk?filter_path=items.*.error
{"delete":{"_index":"product","_id":2}}
{"create":{"_index":"product","_id":2}}
{"name":"_bulk create"}
{"update":{"_index":"product","_id":4}}
{"doc":{"name":"_bulk update 2"}}
{"delete":{"_index":"product","_id":1000}}
{"create":{"_index":"product","_id":2}}
{"name":"_bulk create"}
- 不消耗额外内存
- 可读性查
- 概念
- 以xx开头的搜索,不计算相关度评分
- 注意
- 前缀搜索匹配的是term(倒排索引后的词项),而不是field
- 注意词的拆分
- 如需搜索请配置analyzer的ik_max_word
- 前缀搜索性能很差
- 前缀搜索没有缓存
- 前缀搜索尽可能把前缀长度设置的更长
- 语法
GET <index_name>/_search
{
"query":{
"prefix":{
"<field>":{
"value":"<word_prefix>"
}
}
}
}
index_prefixes: 默认 "min_chars":2,"max_chars":5
- test case
GET /my_index/_search
{
"query": {
"prefix": {
"text": {
"value": "城管"
}
}
}
}
- 配置ik_max_word方便搜索
index_prefiex在索引的基础上(词项)再索引,加快前缀搜索的效率。但占用大量存储空间,不太好。
# index_prefiex在索引的基础上再索引,加快前缀搜索的效率
# eg:
# elasticsearch stack
# elasticsearch search
# el
# ela
PUT my_index
{
"mappings": {
"properties": {
"text": {
"analyzer": "ik_max_word",
"type": "text",
"index_prefixes":{
"min_chars":2,
"max_chars":3
},
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
- 以xx开头的搜索,不计算相关度评分
- 前缀搜索匹配的是term(倒排索引后的词项),而不是field
- 注意词的拆分
- 如需搜索请配置analyzer的ik_max_word
- 前缀搜索性能很差
- 前缀搜索没有缓存
- 前缀搜索尽可能把前缀长度设置的更长
GET <index_name>/_search
{
"query":{
"prefix":{
"<field>":{
"value":"<word_prefix>"
}
}
}
}
index_prefixes: 默认 "min_chars":2,"max_chars":5
GET /my_index/_search
{
"query": {
"prefix": {
"text": {
"value": "城管"
}
}
}
}
index_prefiex在索引的基础上(词项)再索引,加快前缀搜索的效率。但占用大量存储空间,不太好。
# index_prefiex在索引的基础上再索引,加快前缀搜索的效率
# eg:
# elasticsearch stack
# elasticsearch search
# el
# ela
PUT my_index
{
"mappings": {
"properties": {
"text": {
"analyzer": "ik_max_word",
"type": "text",
"index_prefixes":{
"min_chars":2,
"max_chars":3
},
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
通配符运算符是匹配一个或多个字符的占位符。例如,* 通配符运算发匹配0个或多个字符。你可以将通配符与其它字符结合使用以创建通配符模式。
- 注意
- 通配符也匹配的是term,而不是field。
- 注意exact_value匹配时的特殊情况
- 语法
GET <index_name>/_search
{
"query":{
"wildcard":{
"<field>":{
"value":"<word_with_wildcard>"
}
}
}
}
通配符运算符是匹配一个或多个字符的占位符。例如,* 通配符运算发匹配0个或多个字符。你可以将通配符与其它字符结合使用以创建通配符模式。
- 通配符也匹配的是term,而不是field。
- 注意exact_value匹配时的特殊情况
GET <index_name>/_search
{
"query":{
"wildcard":{
"<field>":{
"value":"<word_with_wildcard>"
}
}
}
}
regexp查询的性能可以根据正则表达式而有所不同,为了提高性能,应避免使用统配符模式,如.或.?+未经前缀或后缀
- 语法
GET <index_name>/_search
{
"query":{
"regexp":{
"<field>":{
"value":"<reegexp>",
"flags":"ALL"
}
}
}
}
- flags
flags
说明
例子
ALL启用所有可选操作符。
COMPLEMENT启用~操作符,可以使用~对下面最短的模式进行否定
a~bc # matches 'adc' and 'aec' but not 'abc'
INTERVAL启用<>操作符,可以使用<>匹配数值范围
foo<1-100> # matches 'foo1','foo2'...'foo99','foo100' ; fooo<01-100> # matches 'foo01','foo02'....,'foo99','foo100'
INTERSECTION启用&操作符,它充当AND操作符。如果左边和右边的模式都匹配,则匹配成功。
aaa.+&.+bbb # matches aaabbb
ANYSTRING启用@操作符,你可以使用@来匹配任何整个字符串。你可以将@操作符与&和~操作符组合起来,创造一个"everything except"逻辑
@&~(abc.+) # matches everything except terms beginning with 'abc'
-
test case
GET product_en/_search
{
"query": {
"regexp": {
"title": "[\\s\\S]*nfc[\\s\\S]*"
}
}
}
GET product_en/_search
{
"query": {
"regexp": {
"title": {
"value": "zh~dng",
"flags": "COMPLEMENT"
}
}
}
}
GET /product_en/_search
{
"query": {
"regexp": {
"tags.keyword": {
"value": ".*<2-3>.*",
"flags": "INTERVAL"
}
}
}
}
regexp查询的性能可以根据正则表达式而有所不同,为了提高性能,应避免使用统配符模式,如.或.?+未经前缀或后缀
GET <index_name>/_search
{
"query":{
"regexp":{
"<field>":{
"value":"<reegexp>",
"flags":"ALL"
}
}
}
}
| flags | 说明 | 例子 |
|---|---|---|
ALL |
启用所有可选操作符。 | |
COMPLEMENT |
启用~操作符,可以使用~对下面最短的模式进行否定 | a~bc # matches 'adc' and 'aec' but not 'abc' |
INTERVAL |
启用<>操作符,可以使用<>匹配数值范围 | foo<1-100> # matches 'foo1','foo2'...'foo99','foo100' ; fooo<01-100> # matches 'foo01','foo02'....,'foo99','foo100' |
INTERSECTION |
启用&操作符,它充当AND操作符。如果左边和右边的模式都匹配,则匹配成功。 | aaa.+&.+bbb # matches aaabbb |
ANYSTRING |
启用@操作符,你可以使用@来匹配任何整个字符串。你可以将@操作符与&和~操作符组合起来,创造一个"everything except"逻辑 | @&~(abc.+) # matches everything except terms beginning with 'abc' |
test case
GET product_en/_search
{
"query": {
"regexp": {
"title": "[\\s\\S]*nfc[\\s\\S]*"
}
}
}
GET product_en/_search
{
"query": {
"regexp": {
"title": {
"value": "zh~dng",
"flags": "COMPLEMENT"
}
}
}
}
GET /product_en/_search
{
"query": {
"regexp": {
"tags.keyword": {
"value": ".*<2-3>.*",
"flags": "INTERVAL"
}
}
}
}
混淆字符 box > fox ; 缺少字符 black > lack ;多出字符 sic > sic ;颠倒词序 act > cat
- 语法
GET <index_name>/_search
{
"query":{
"fuzzy":{
"<field>":{
"value":"<keyword>"
}
}
}
}
- 参数
- value:必须,关键字
- fuzziness: 编辑距离,(0,1,2)并非越大越好,召回率高但结果不准确。
- 两段文本之间的Damerau-Levenshtein距离是使一个字符串与另一个字符串匹配所需的插入、删除、替换和调换的数量
- 距离公式:
- Levenshtein是lucene的 es改进版:Damerau-Levenshtein.
axe=>aex Levenshtein=2 Damerau-Levenshtein=1
- transpositions: (可选,布尔值)指示编辑是否包括两个相邻字符的变位(ab→ba),默认为true
- test case
GET /product_en/_search
{
"query": {
"fuzzy": {
"desc":"quangengneng"
}
}
}
- match也可以用fuzziness,但match是分词的,fuzzy是不分词的。
GET /product_en/_search
{
"query": {
"match": {
"desc":{
"query": "quangongneng",
"fuzziness": 1
}
}
}
}
混淆字符 box > fox ; 缺少字符 black > lack ;多出字符 sic > sic ;颠倒词序 act > cat
GET <index_name>/_search
{
"query":{
"fuzzy":{
"<field>":{
"value":"<keyword>"
}
}
}
}
- value:必须,关键字
- fuzziness: 编辑距离,(0,1,2)并非越大越好,召回率高但结果不准确。
- 两段文本之间的Damerau-Levenshtein距离是使一个字符串与另一个字符串匹配所需的插入、删除、替换和调换的数量
- 距离公式:
- Levenshtein是lucene的 es改进版:Damerau-Levenshtein.
axe=>aex Levenshtein=2 Damerau-Levenshtein=1
- Levenshtein是lucene的 es改进版:Damerau-Levenshtein.
- transpositions: (可选,布尔值)指示编辑是否包括两个相邻字符的变位(ab→ba),默认为true
GET /product_en/_search
{
"query": {
"fuzzy": {
"desc":"quangengneng"
}
}
}
GET /product_en/_search
{
"query": {
"match": {
"desc":{
"query": "quangongneng",
"fuzziness": 1
}
}
}
}
- match_phrase:
- match_phrase会分词
- 被检索字段必须包含match_phrase中的所有词项并且顺序必须是相同的
- 被检索字段包含的match_phrase中的词项之间不能有其他词项【即查询字段应该在查询结果中(检索字段)是连续的】
match_phrase_prefix与match_phrase相同,但是它多了一个特性就是它允许在文本的最后一个词项(term)上的前缀匹配,如果是一个单词,比如a,它会匹配文 档字段所有以a开头的文档如果是一个短语,比如"this is ma",他会先在倒排索引中做以ma做前缀搜索,然后在匹配到的doc中做match_phrase查询(网上有的说是先match_phrase,然后再进行前级搜索,是不对的)
- 参数
- analyzer 指定何种分析器来对该短语进行分词处理
- max_expansions 限制匹配的最大词项
- boost 用于设置该查询的权重
- slop 允许短语间的词项(term)间隔: slop 参数告诉 match_phrase 查询词条相隔多运时仍然能将文档视为匹配
- 什么是相隔多远?意思是说为了让查询和 文档匹配你需要移动词条多少次
- 原理解析:https://www.elastic.co/cn/blog/found-fuzzy-search=performance-considerations
GET /product_en/_search
{
"query": {
"match_phrase_prefix": {
"desc": {
"query": "shouji zhong d",
"max_expansions": 1
}
}
}
}
# 注意slop的理解
GET /product_en/_search
{
"query": {
"match_phrase_prefix": {
"desc": {
"query": "zhong hongzhaji",
"max_expansions": 50,
"slop":1
}
}
}
}
- match_phrase会分词
- 被检索字段必须包含match_phrase中的所有词项并且顺序必须是相同的
- 被检索字段包含的match_phrase中的词项之间不能有其他词项【即查询字段应该在查询结果中(检索字段)是连续的】
match_phrase_prefix与match_phrase相同,但是它多了一个特性就是它允许在文本的最后一个词项(term)上的前缀匹配,如果是一个单词,比如a,它会匹配文 档字段所有以a开头的文档如果是一个短语,比如"this is ma",他会先在倒排索引中做以ma做前缀搜索,然后在匹配到的doc中做match_phrase查询(网上有的说是先match_phrase,然后再进行前级搜索,是不对的)
- analyzer 指定何种分析器来对该短语进行分词处理
- max_expansions 限制匹配的最大词项
- boost 用于设置该查询的权重
- slop 允许短语间的词项(term)间隔: slop 参数告诉 match_phrase 查询词条相隔多运时仍然能将文档视为匹配
- 什么是相隔多远?意思是说为了让查询和 文档匹配你需要移动词条多少次
GET /product_en/_search
{
"query": {
"match_phrase_prefix": {
"desc": {
"query": "shouji zhong d",
"max_expansions": 1
}
}
}
}
# 注意slop的理解
GET /product_en/_search
{
"query": {
"match_phrase_prefix": {
"desc": {
"query": "zhong hongzhaji",
"max_expansions": 50,
"slop":1
}
}
}
}
性能比其它更好,但更占用磁盘空间
- ngram
# ngram 和 edge-ngram
# tokenizer
GET _analyze
{
"tokenizer": "ngram",
"text": "reba always loves me"
}
# min_gram = 1 "max_gram":2
# token filter 词项过滤器
GET _analyze
{
"tokenizer": "standard",
"filter": ["ngram"],
"text": "reba always loves me"
}
# min_gram = 1 "max_gram": 1
# r a l m
# min_gram = 1 "max_gram": 2
# r a l m
# re al lo me
# min_gram = 2 "max_gram": 3
# re al lo mee
# reb alw lov me
PUT ngram_index
{
"settings": {
"analysis": {
"filter": {
"2_3_ngram":{
"type":"ngram",
"min_gram":2,
"max_gram":3
}
},
"analyzer": {
"my_ngram":{
"type":"custom",
"tokenizer":"standard",
"filter":["2_3_ngram"]
}
}
}
},
"mappings": {
"properties": {
"text":{
"type": "text",
"analyzer": "my_ngram",
"search_analyzer": "standard"
}
}
}
}
GET ngram_index/_mapping
POST /ngram_index/_bulk
{ "index": { "_id": "1"} }
{"text": "my english" }
{ "index": { "_id": "2"}}
{"text": "my english is good" }
{ "index": { "_id": "3"} }
{"text": "my chinese is good" }
{ "index": { "_id": "4"}}
{"text": "my japanese is nice" }
{ "index": { "_id": "5"} }
{"text": "my disk is full" }
GET ngram_index/_search
GET ngram_index/_mapping
# 因为配置了2-3的ngram所以能够搜索到
GET ngram_index/_search
{
"query": {
"match_phrase": {
"text": "my eng is goo"
}
}
}
GET ngram_index/_search
{
"query": {
"match_phrase": {
"text": "my en is goo"
}
}
}
- edge ngram
DELETE edge_ngram_index
GET /_analyze
{
"tokenizer": "standard",
"filter": ["edge_ngram"],
"text": "reba always loves me"
}
PUT edge_ngram_index
{
"settings": {
"analysis": {
"filter": {
"edge_gram":{
"type":"edge_ngram",
"min_gram":2,
"max_gram":3
}
},
"analyzer": {
"my_edge_gram":{
"type":"custom",
"tokenizer":"standard",
"filter":["edge_gram"]
}
}
}
},
"mappings": {
"properties": {
"text":{
"type": "text",
"analyzer": "my_edge_gram",
"search_analyzer": "standard"
}
}
}
}
POST /edge_ngram_index/_bulk
{ "index": { "_id": "1"} }
{"text": "my english" }
{ "index": { "_id": "2"}}
{"text": "my english is good" }
{ "index": { "_id": "3"} }
{"text": "my chinese is good" }
{ "index": { "_id": "4"}}
{"text": "my japanese is nice" }
{ "index": { "_id": "5"} }
{"text": "my disk is full" }
GET edge_ngram_index/_search
{
"query": {
"match_phrase": {
"text": "my en is goo"
}
}
}
性能比其它更好,但更占用磁盘空间
# ngram 和 edge-ngram
# tokenizer
GET _analyze
{
"tokenizer": "ngram",
"text": "reba always loves me"
}
# min_gram = 1 "max_gram":2
# token filter 词项过滤器
GET _analyze
{
"tokenizer": "standard",
"filter": ["ngram"],
"text": "reba always loves me"
}
# min_gram = 1 "max_gram": 1
# r a l m
# min_gram = 1 "max_gram": 2
# r a l m
# re al lo me
# min_gram = 2 "max_gram": 3
# re al lo mee
# reb alw lov me
PUT ngram_index
{
"settings": {
"analysis": {
"filter": {
"2_3_ngram":{
"type":"ngram",
"min_gram":2,
"max_gram":3
}
},
"analyzer": {
"my_ngram":{
"type":"custom",
"tokenizer":"standard",
"filter":["2_3_ngram"]
}
}
}
},
"mappings": {
"properties": {
"text":{
"type": "text",
"analyzer": "my_ngram",
"search_analyzer": "standard"
}
}
}
}
GET ngram_index/_mapping
POST /ngram_index/_bulk
{ "index": { "_id": "1"} }
{"text": "my english" }
{ "index": { "_id": "2"}}
{"text": "my english is good" }
{ "index": { "_id": "3"} }
{"text": "my chinese is good" }
{ "index": { "_id": "4"}}
{"text": "my japanese is nice" }
{ "index": { "_id": "5"} }
{"text": "my disk is full" }
GET ngram_index/_search
GET ngram_index/_mapping
# 因为配置了2-3的ngram所以能够搜索到
GET ngram_index/_search
{
"query": {
"match_phrase": {
"text": "my eng is goo"
}
}
}
GET ngram_index/_search
{
"query": {
"match_phrase": {
"text": "my en is goo"
}
}
}
DELETE edge_ngram_index
GET /_analyze
{
"tokenizer": "standard",
"filter": ["edge_ngram"],
"text": "reba always loves me"
}
PUT edge_ngram_index
{
"settings": {
"analysis": {
"filter": {
"edge_gram":{
"type":"edge_ngram",
"min_gram":2,
"max_gram":3
}
},
"analyzer": {
"my_edge_gram":{
"type":"custom",
"tokenizer":"standard",
"filter":["edge_gram"]
}
}
}
},
"mappings": {
"properties": {
"text":{
"type": "text",
"analyzer": "my_edge_gram",
"search_analyzer": "standard"
}
}
}
}
POST /edge_ngram_index/_bulk
{ "index": { "_id": "1"} }
{"text": "my english" }
{ "index": { "_id": "2"}}
{"text": "my english is good" }
{ "index": { "_id": "3"} }
{"text": "my chinese is good" }
{ "index": { "_id": "4"}}
{"text": "my japanese is nice" }
{ "index": { "_id": "5"} }
{"text": "my disk is full" }
GET edge_ngram_index/_search
{
"query": {
"match_phrase": {
"text": "my en is goo"
}
}
}
搜索一般都会要求具有“搜索推荐“或者叫"按索补全”的功能,即在用户输入提索的过程中,进行自动补全或者纠错以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验,这就是Suggest.
搜索一般都会要求具有“搜索推荐“或者叫"按索补全”的功能,即在用户输入提索的过程中,进行自动补全或者纠错以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验,这就是Suggest.
term suggester正如其名只基于tokenizer之后的单个term去匹配建议词(针对单独term的搜索推荐),并不会考虑多个term之间的关系
- 语法
POST <index_name>/_search
{
"suggest":{
"<suggest_name>": {
"text":"<search_content>",
"term" {
"suggest_mode": "<suggest mode>"
"field":"<field_name>"
}
}
}
}
- Options:
- text: 用户搜索的文本
- field要从哪个字段选取推荐数据
- analyzer使用哪种分词器:
- size每个建议返回的最大结果数
- sort:如何按照提示词項排序,参数值只可以是以下两个枚举:
- score:分数>词频>词填本身
- frequency: 词频>分数>词本身
- suggest_mode搜索推荐的推荐模式参数值亦是枚举:
- missing: 默认值。仅为不在索引中的词项生成建议词
- popular: 仅返回与搜索词文档词频文档词频更高的建议词
- always: 根据建议文本中的词项推荐任何匹配的建议词
- max_edits:可以根据具有最大偏移量距离候选建议以便认为是建议。只能是1-2之间的值,其它任何值都将导致xxx
- prefix_length:前缀匹配的时候,必须满足的最少字符
- min_word_length: 最少包含的单词数量
- min_doc_freq: 最少的文档频率
- max_term_freq: 最大词频率
- test case
DELETE news
POST _bulk
{"index":{"_index":"news","_id":1}}
{"title":"baoqiang bought a new hat with the same color of this font, which is very beautiful baoqiangba baoqiangda baoqiangdada baoqian baoqia"}
{"index":{"_index":"news","_id":2}}
{"title":"baoqiangge gave birth to two children, one is upstairs, one is downstairs baoqiangba baoqiangda baoqiangdada baoqian baoqia"}
{"index":{"_index":"news","_id":3}}
{"title":"booqiangge 's money was rolled away baoqiangba baoqiangda baoqiangdada baoqian baoqia"}
{"index":{"_index":"news","_id":4}}
{"title":"baoqiangda baoqiangda baoqiangda baoqiangda baoqiangda baoqian baoqia"}
GET news/_mapping
# baoqing是故意输错的
# 返回结果的freq是指文档的个数
POST news/_search
{
"suggest": {
"my-suggestion": {
"text": "baoqing baoqiang",
"term": {
"suggest_mode": "popular",
"field": "title",
"min_doc_freq":3
}
}
}
}
term suggester正如其名只基于tokenizer之后的单个term去匹配建议词(针对单独term的搜索推荐),并不会考虑多个term之间的关系
POST <index_name>/_search
{
"suggest":{
"<suggest_name>": {
"text":"<search_content>",
"term" {
"suggest_mode": "<suggest mode>"
"field":"<field_name>"
}
}
}
}
- text: 用户搜索的文本
- field要从哪个字段选取推荐数据
- analyzer使用哪种分词器:
- size每个建议返回的最大结果数
- sort:如何按照提示词項排序,参数值只可以是以下两个枚举:
- score:分数>词频>词填本身
- frequency: 词频>分数>词本身
- suggest_mode搜索推荐的推荐模式参数值亦是枚举:
- missing: 默认值。仅为不在索引中的词项生成建议词
- popular: 仅返回与搜索词文档词频文档词频更高的建议词
- always: 根据建议文本中的词项推荐任何匹配的建议词
- max_edits:可以根据具有最大偏移量距离候选建议以便认为是建议。只能是1-2之间的值,其它任何值都将导致xxx
- prefix_length:前缀匹配的时候,必须满足的最少字符
- min_word_length: 最少包含的单词数量
- min_doc_freq: 最少的文档频率
- max_term_freq: 最大词频率
DELETE news
POST _bulk
{"index":{"_index":"news","_id":1}}
{"title":"baoqiang bought a new hat with the same color of this font, which is very beautiful baoqiangba baoqiangda baoqiangdada baoqian baoqia"}
{"index":{"_index":"news","_id":2}}
{"title":"baoqiangge gave birth to two children, one is upstairs, one is downstairs baoqiangba baoqiangda baoqiangdada baoqian baoqia"}
{"index":{"_index":"news","_id":3}}
{"title":"booqiangge 's money was rolled away baoqiangba baoqiangda baoqiangdada baoqian baoqia"}
{"index":{"_index":"news","_id":4}}
{"title":"baoqiangda baoqiangda baoqiangda baoqiangda baoqiangda baoqian baoqia"}
GET news/_mapping
# baoqing是故意输错的
# 返回结果的freq是指文档的个数
POST news/_search
{
"suggest": {
"my-suggestion": {
"text": "baoqing baoqiang",
"term": {
"suggest_mode": "popular",
"field": "title",
"min_doc_freq":3
}
}
}
}
在term suggester的基础上考虑多个term之间的关系,比如哦是否同时在同一个索引原文中,相邻程度以及词频等等。
- test case
#phrase suggester
DELETE test
PUT test
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"trigram": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"shingle"
]
}
},
"filter": {
"shingle":{
"type": "shingle",
"min shingle_size": 2,
"max_shingle_size": 3
}
}
}
}
},
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"trigram":{
"type":"text",
"analyzer":"trigram"
}
}
}
}
}
}
POST test/_bulk
{"index":{"_id":1}}
{"title":"lucene and elasticsearch"}
{"index":{"_id":2}}
{"title":"lucene and elasticsearhc"}
{"index":{"_id":3}}
{"title":"luceen and elasticsearch"}
GET test/_analyze
{
"analyzer": "standard",
"text": "lucene and elasticsearch"
}
GET test/_search
{
"suggest": {
"text": "Luceen and elasticsearhc",
"simple_phrase": {
"phrase": {
"field": "title.trigram",
//可信度
"confidence":0,
"max_errors": 2,
"direct_generator": [
{
"field": "title.trigram",
"suggest_mode": "always"
}
],
"highlight":{
"pre_tag":"<em>",
"post_tag":"</em>"
}
}
}
}
}
在term suggester的基础上考虑多个term之间的关系,比如哦是否同时在同一个索引原文中,相邻程度以及词频等等。
#phrase suggester
DELETE test
PUT test
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"trigram": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"shingle"
]
}
},
"filter": {
"shingle":{
"type": "shingle",
"min shingle_size": 2,
"max_shingle_size": 3
}
}
}
}
},
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"trigram":{
"type":"text",
"analyzer":"trigram"
}
}
}
}
}
}
POST test/_bulk
{"index":{"_id":1}}
{"title":"lucene and elasticsearch"}
{"index":{"_id":2}}
{"title":"lucene and elasticsearhc"}
{"index":{"_id":3}}
{"title":"luceen and elasticsearch"}
GET test/_analyze
{
"analyzer": "standard",
"text": "lucene and elasticsearch"
}
GET test/_search
{
"suggest": {
"text": "Luceen and elasticsearhc",
"simple_phrase": {
"phrase": {
"field": "title.trigram",
//可信度
"confidence":0,
"max_errors": 2,
"direct_generator": [
{
"field": "title.trigram",
"suggest_mode": "always"
}
],
"highlight":{
"pre_tag":"<em>",
"post_tag":"</em>"
}
}
}
}
}
基于内存而非索引,性能强悍 / 需要结合特定的completion类型/只适合前缀
自动补全,自动完成,支持三种查询【前缀查询(prefix)模糊查询(fuzzy) 正则表达式查询(regex)】,主要针对的应用场 景就是"Auto Completion", 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响 应速度要求比较苛刻,因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起 存放,对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快,但是FST只能用于前缀查找,这也是Completion Suggester的用 限所在。
- completion:函的一种特有类型,专门为suggest提供,基于内存,性能很高。
- prefix query:基于前缀查询的搜索提示,是最常用的一种搜索推荐查询。
- prefix:客户端搜索词
- field:建议词字段
- size: 需要返回的建议词数量(默认5)
- skip_duplicates: 是否过滤掉重复建议,默认false
- fuzzy query
- fuzziness: 允许的偏移量,默认auto
- transpositions: 如果设置为true,则换位计为一次更改而不是两次更改,默认为true。
- min_length:返回模糊建议之前的最小输入长度,默认3
- prefix_length:输入的最小长度(不检查模糊替代项)默认为1
- unicode_aware:如果为true,则所有度量(如模糊编辑距离,换位和长度)均以Unicode代码点而不是以字节为单位,这比原始字节略慢,因此默 认情况下将其设置为false。
- regex query:可以用正则表示前缀,不建议使用
-
test case
DELETE suggest_carinfo
PUT suggest_carinfo
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"suggest":{
"type":"completion",
"analyzer":"ik_max_word"
}
}
},
"content":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST _bulk
{"index":{"_index": "suggest_carinfo","_id":1}}
{"title":"宝马X5 两万公里准新车","content":"这里是宝马X5图文描述"}
{"index":{"_index": "suggest_carinfo","_id":2}}
{"title":"宝马5系","content":"这里是奥迪A6图文描述"}
{"index":{"_index":"suggest_carinfo","_id":3}}
{"title":"宝马3系","content":"这里是奔驰图文描述"}
{"index":{"_index":"suggest_carinfo","_id":4}}
{"title":"奥迪Q5 两万公里准新车","content":"这里是宝马X5图文描述"}
{"index":{"_index": "suggest_carinfo","_id":5}}
{"title":"奥迪A6 无敌车况","content":"这里是奥迪A6图文描述"}
{"index":{"_index": "suggest_carinfo","_id":6}}
{"title":"奥迪双钻","content":"这里是奔驰图文描述"}
{"index":{"_index": "suggest_carinfo","_id":7}}
{"title":"奔驰AMG 两万公里准新车","content":"这里是宝马X5图文描述"}
{"index":{"_index": "suggest_carinfo","_id":8}}
{"title":"奔驰大G 无敌车况","content":"这里是奥迪A6图文描述"}
{"index":{"_index":"suggest_carinfo","_id":9}}
{"title":"奔驰C260","content":"这里是奔驰图文描述"}
{"index":{"_index": "suggest_carinfo", "_id":10}}
{"title":"nir奔驰C260","content":"这里是奔驰图文描述"}
# 语法
GET suggest_carinfo/_search
{
"suggest": {
"car_suggest": {
"prefix":"奥迪",
"completion":{
"field":"title.suggest"
}
}
}
}
# fuzzy
GET suggest_carinfo/_search
{
"suggest": {
"car_suggest": {
"prefix":"宝马5系",
"completion":{
"field":"title.suggest",
"skip_duplicates":true,
"fuzzy":{
"fuzziness":2
}
}
}
}
}
#正则
GET suggest_carinfo/_search
{
"suggest": {
"car_suggest": {
"regex":"nir",
"completion":{
"field":"title.suggest",
"size":10
}
}
}
}
基于内存而非索引,性能强悍 / 需要结合特定的completion类型/只适合前缀
自动补全,自动完成,支持三种查询【前缀查询(prefix)模糊查询(fuzzy) 正则表达式查询(regex)】,主要针对的应用场 景就是"Auto Completion", 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响 应速度要求比较苛刻,因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起 存放,对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快,但是FST只能用于前缀查找,这也是Completion Suggester的用 限所在。
- prefix:客户端搜索词
- field:建议词字段
- size: 需要返回的建议词数量(默认5)
- skip_duplicates: 是否过滤掉重复建议,默认false
- fuzziness: 允许的偏移量,默认auto
- transpositions: 如果设置为true,则换位计为一次更改而不是两次更改,默认为true。
- min_length:返回模糊建议之前的最小输入长度,默认3
- prefix_length:输入的最小长度(不检查模糊替代项)默认为1
- unicode_aware:如果为true,则所有度量(如模糊编辑距离,换位和长度)均以Unicode代码点而不是以字节为单位,这比原始字节略慢,因此默 认情况下将其设置为false。
test case
DELETE suggest_carinfo
PUT suggest_carinfo
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"suggest":{
"type":"completion",
"analyzer":"ik_max_word"
}
}
},
"content":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST _bulk
{"index":{"_index": "suggest_carinfo","_id":1}}
{"title":"宝马X5 两万公里准新车","content":"这里是宝马X5图文描述"}
{"index":{"_index": "suggest_carinfo","_id":2}}
{"title":"宝马5系","content":"这里是奥迪A6图文描述"}
{"index":{"_index":"suggest_carinfo","_id":3}}
{"title":"宝马3系","content":"这里是奔驰图文描述"}
{"index":{"_index":"suggest_carinfo","_id":4}}
{"title":"奥迪Q5 两万公里准新车","content":"这里是宝马X5图文描述"}
{"index":{"_index": "suggest_carinfo","_id":5}}
{"title":"奥迪A6 无敌车况","content":"这里是奥迪A6图文描述"}
{"index":{"_index": "suggest_carinfo","_id":6}}
{"title":"奥迪双钻","content":"这里是奔驰图文描述"}
{"index":{"_index": "suggest_carinfo","_id":7}}
{"title":"奔驰AMG 两万公里准新车","content":"这里是宝马X5图文描述"}
{"index":{"_index": "suggest_carinfo","_id":8}}
{"title":"奔驰大G 无敌车况","content":"这里是奥迪A6图文描述"}
{"index":{"_index":"suggest_carinfo","_id":9}}
{"title":"奔驰C260","content":"这里是奔驰图文描述"}
{"index":{"_index": "suggest_carinfo", "_id":10}}
{"title":"nir奔驰C260","content":"这里是奔驰图文描述"}
# 语法
GET suggest_carinfo/_search
{
"suggest": {
"car_suggest": {
"prefix":"奥迪",
"completion":{
"field":"title.suggest"
}
}
}
}
# fuzzy
GET suggest_carinfo/_search
{
"suggest": {
"car_suggest": {
"prefix":"宝马5系",
"completion":{
"field":"title.suggest",
"skip_duplicates":true,
"fuzzy":{
"fuzziness":2
}
}
}
}
}
#正则
GET suggest_carinfo/_search
{
"suggest": {
"car_suggest": {
"regex":"nir",
"completion":{
"field":"title.suggest",
"size":10
}
}
}
}
context suggester: 完成建议者会考虑索引中的所有文档,但是通常希望提供由某些条件过滤和/或增强的建议。
- test case
#定义一个名为place_type 的类别上下文,其中类别必须与建议一起发送。
#定义一个名为 location 的地理上下文,类别必须与建议一起发送
DELETE place
PUT place
{
"mappings": {
"properties": {
"suggest": {
"type": "completion",
"contexts": [
{
"name": "place_type",
"type": "category"
},
{
"name": "location",
"type": "geo",
"precision": 4
}
]
}
}
}
}
GET place/_mapping
PUT place/_doc/1
{
"suggest": {
"input": [
"timmy's",
"starbucks",
"dunkin donuts"
],
"contexts": {
"place_type": [
"cafe",
"food"
]
}
}
}
PUT place/_doc/2
{
"suggest": {
"input": [
"monkey",
"timmy's",
"Lamborghini"
],
"contexts": {
"place_type": [
"money"
]
}
}
}
GET place/_search
POST place/_search?pretty
{
"suggest": {
"place_suggestions": {
"prefix":"sta",
"completion":{
"field":"suggest",
"size":10,
"contexts":{
"place_type":["cafe","restaurants"]
}
}
}
}
}
# boost提升权重用法
POST place/_search?pretty
{
"suggest": {
"place_suggestions": {
"prefix": "sta",
"completion": {
"field": "suggest",
"size": 10,
"contexts": {
"place_type": [
{
"context": "cafe"
},
{
"context": "money",
"boost": 2
}
]
}
}
}
}
}
PUT place/_doc/3
{
"suggest": {
"input": "timmy's",
"contexts": {
"location": [
{
"lat": 43.6624803,
"lon": -79.3863353
},
{
"lat": 43.6624718,
"lon": -79.3878227
}
]
}
}
}
GET place/_search
{
"suggest": {
"place_suggestion": {
"prefix": "tim",
"completion": {
"field": "suggest",
"size": 10,
"contexts": {
"location":{
"lat":43.662,
"lon":-79.380
}
}
}
}
}
}
#定义一个名为 place type 的类别上下文,其中类别是从 cat字段中读取的。
#定义一个名为 location 的地理上下文,其中的类别是从 loc字段中读取的。
DELETE place_path_category
PUT place_path_category
{
"mappings": {
"properties": {
"suggest": {
"type": "completion",
"contexts": [
{
"name": "place_type",
"type": "category",
"path": "cat"
},
{
"name": "location",
"type": "geo",
"precision": 4,
"path": "loc"
}
]
},
"loc": {
"type": "geo_point"
}
}
}
}
#如果映射有路径,那么以下索引请求就足以添加类别
#这些建议将与咖啡馆和食品类别另一个字段并且类别被明确索引,则建议将使用两组类别进行索引
PUT place_path_category/_doc/1
{
"suggest": [
"timmy's",
"starbucks",
"dunkin donuts"
],
"cat": [
"cafe",
"food"
]
}
POST place_path_category/_search?pretty
{
"suggest": {
"place_suggestion": {
"prefix": "tim",
"completion": {
"field": "suggest",
"context": {
"place_type": [
{
"context": "cafe"
}
]
}
}
}
}
}
context suggester: 完成建议者会考虑索引中的所有文档,但是通常希望提供由某些条件过滤和/或增强的建议。
#定义一个名为place_type 的类别上下文,其中类别必须与建议一起发送。
#定义一个名为 location 的地理上下文,类别必须与建议一起发送
DELETE place
PUT place
{
"mappings": {
"properties": {
"suggest": {
"type": "completion",
"contexts": [
{
"name": "place_type",
"type": "category"
},
{
"name": "location",
"type": "geo",
"precision": 4
}
]
}
}
}
}
GET place/_mapping
PUT place/_doc/1
{
"suggest": {
"input": [
"timmy's",
"starbucks",
"dunkin donuts"
],
"contexts": {
"place_type": [
"cafe",
"food"
]
}
}
}
PUT place/_doc/2
{
"suggest": {
"input": [
"monkey",
"timmy's",
"Lamborghini"
],
"contexts": {
"place_type": [
"money"
]
}
}
}
GET place/_search
POST place/_search?pretty
{
"suggest": {
"place_suggestions": {
"prefix":"sta",
"completion":{
"field":"suggest",
"size":10,
"contexts":{
"place_type":["cafe","restaurants"]
}
}
}
}
}
# boost提升权重用法
POST place/_search?pretty
{
"suggest": {
"place_suggestions": {
"prefix": "sta",
"completion": {
"field": "suggest",
"size": 10,
"contexts": {
"place_type": [
{
"context": "cafe"
},
{
"context": "money",
"boost": 2
}
]
}
}
}
}
}
PUT place/_doc/3
{
"suggest": {
"input": "timmy's",
"contexts": {
"location": [
{
"lat": 43.6624803,
"lon": -79.3863353
},
{
"lat": 43.6624718,
"lon": -79.3878227
}
]
}
}
}
GET place/_search
{
"suggest": {
"place_suggestion": {
"prefix": "tim",
"completion": {
"field": "suggest",
"size": 10,
"contexts": {
"location":{
"lat":43.662,
"lon":-79.380
}
}
}
}
}
}
#定义一个名为 place type 的类别上下文,其中类别是从 cat字段中读取的。
#定义一个名为 location 的地理上下文,其中的类别是从 loc字段中读取的。
DELETE place_path_category
PUT place_path_category
{
"mappings": {
"properties": {
"suggest": {
"type": "completion",
"contexts": [
{
"name": "place_type",
"type": "category",
"path": "cat"
},
{
"name": "location",
"type": "geo",
"precision": 4,
"path": "loc"
}
]
},
"loc": {
"type": "geo_point"
}
}
}
}
#如果映射有路径,那么以下索引请求就足以添加类别
#这些建议将与咖啡馆和食品类别另一个字段并且类别被明确索引,则建议将使用两组类别进行索引
PUT place_path_category/_doc/1
{
"suggest": [
"timmy's",
"starbucks",
"dunkin donuts"
],
"cat": [
"cafe",
"food"
]
}
POST place_path_category/_search?pretty
{
"suggest": {
"place_suggestion": {
"prefix": "tim",
"completion": {
"field": "suggest",
"context": {
"place_type": [
{
"context": "cafe"
}
]
}
}
}
}
}
- https://github.com/medcl/elasticsearch-analysis-ik
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
root@020ba19969e9:/usr/share/elasticsearch/bin# elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
-> Installing https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
[=================================================] 100%??
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See https://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-ik
-> Please restart Elasticsearch to activate any plugins installed
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
root@020ba19969e9:/usr/share/elasticsearch/bin# elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
-> Installing https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
[=================================================] 100%??
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See https://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-ik
-> Please restart Elasticsearch to activate any plugins installed




